AI Ops e Automação Preditiva: Como Aplicar para Diminuir Gastos Operacionais

Já pensou quanto sua operação poderia economizar se problemas fossem resolvidos antes mesmo de aparecerem? Aplicar AI Ops e automação preditiva reduz gastos operacionais ao prever falhas, priorizar intervenções, otimizar uso de infraestrutura e automatizar tarefas repetitivas, diminuindo tempo de inatividade, retrabalho e horas de suporte. Isso é crucial num cenário em que pequenas ineficiências viram custos enormes: você vai entender por que a abordagem muda o jogo, quais problemas devem ser endereçados primeiro, quais métricas acompanhar e passos práticos para começar a implementar soluções que geram economia real e mensurável.
1. O que é AI Ops e automação preditiva: definição e relação com custos
Definimos AI Ops como a aplicação de IA para operar, correlacionar e automatizar observabilidade; automação preditiva antecipa falhas e demanda. Este item esclarece como esses dois pilares reduzem despesas operacionais.
Foco operacional: do alerta reativo à ação automática
Nós entendemos AI Ops como um conjunto de práticas que integra ingestão de logs, correlação de eventos e modelos de ML para priorizar problemas automaticamente. Em ambientes com centenas de servidores, AI Ops diminui MTTR em 30–60% quando aplicado a diagnóstico de incidentes, reduzindo horas pagas de resposta e horas extras. A integração com runbooks automatizados transforma diagnósticos em correções sem intervenção manual.
Automação preditiva complementa AI Ops ao identificar padrões antes da ocorrência — degradação de I/O, aumento de latência ou queda gradual de capacidade. Em casos concretos, prever degradação com 7 dias de antecedência permite reagendar janelas de manutenção e evitar escalonamentos emergenciais, cortando custos de suporte terceirizado. Implementamos esse fluxo com pipelines de dados e modelos supervisionados treinados em séries temporais.
Na prática, combinamos AI Ops e automação preditiva para reduzir custos diretos (contratos de suporte, horas de plantão) e indiretos (perda de receita por downtime). Integramos alertas preditivos a ferramentas de orquestração e a AI, automação e negócios: visão integrada, garantindo que decisões de escalonamento sejam baseadas em probabilidade e custo-benefício, não apenas em regras estáticas.
Característica: correlação automática de eventos por causa raiz
Funcionalidade exclusiva: acionamento de playbooks de correção sem intervenção humana
Caso de uso: previsão de falhas de armazenamento com janela de 72 horas
Indicador monitorado | Contexto ou explicação |
Indicador monitorado | Contexto ou explicação |
Ticket médio mensal | R$ 480 considerando planos com fidelidade em 2024 |
Taxa de renovação anual | 82% dos contratos com suporte personalizado |
Priorize modelos que entreguem previsões com lead time útil (48–168 horas) e ROI mensurável em redução de horas de suporte.
Ao detalhar esse item, nós identificamos ações imediatas: instrumentar métricas críticas, treinar modelos e automatizar playbooks para cortar custos operacionais.
2. Benefícios diretos na redução de gastos operacionais
Como item focal, descrevemos economias mensuráveis que surgem ao aplicar AI Ops e automação preditiva: redução de manutenção corretiva, diminuição do tempo de inatividade e alocação mais eficiente da equipe técnica em atividades de maior valor.
Redução imediata de custos com foco em ações preventivas
Nós observamos três frentes de economia direta: manutenção, disponibilidade e produtividade do time. A substituição de tarefas reativas por intervenções preditivas reduz ordens de serviço emergenciais em até 40% em ambientes instrumentados, cortando custos premium de peça e hora extra. Quando combinamos monitoramento contínuo e modelos de anomalia, o custo por incidente tende a diminuir progressivamente conforme o modelo se ajusta ao ambiente.
Em exemplos práticos, clientes que ativaram pipelines de AI Ops reduziram tempo de inatividade não planejado de 6 para 2 horas mensais em sistemas críticos, gerando economia operacional direta por evitar perda de receita e horas de recuperação. Vinculamos essas métricas a processos de suporte para recalibrar SLAs e liberar orçamento: ver Como reduzir custos com TI de forma prática para ações tangíveis que complementam automação.
Além disso, automação preditiva melhora alocação de pessoal: nós realocamos 20–30% do esforço de triagem para projetos de otimização quando rotinas de diagnóstico foram automatizadas. Essa mudança transforma custos fixos de operação em investimentos de melhoria contínua, reduzindo churn interno e o custo médio por ticket. A integração de AI Ops automação preditiva custos aparece naturalmente no cálculo do ROI ao contabilizar horas recuperadas e falhas evitadas.
Manutenção preventiva automatizada — diminui ordens emergenciais e peça de reposição de alto custo.
Redução do tempo de inatividade — menos perda de receita e menor uso de recursos de recuperação.
Eficiência da equipe — reaproveitamento de horas de triagem para projetos estratégicos.
Otimização de contratos de suporte — renegociação baseada em dados concretos de incidentes evitados.
Indicador monitorado | Contexto ou explicação |
Indicador monitorado | Contexto ou explicação |
Ticket médio mensal | R$ 480 considerando planos com fidelidade em 2024 |
Taxa de renovação anual | 82% dos contratos com suporte personalizado |
Priorize métricas de tempo médio para detecção e resolução; 30% de ganho nessas métricas costuma traduzir-se em economia operacional mensurável.
Ao detalhar economias por manutenção, downtime e produtividade, nós entregamos parâmetros claros para estimar retorno e priorizar automações com impacto financeiro imediato.
3. Casos de uso práticos: onde aplicar automação preditiva em TI e operações
Como item 3 da lista, detalhamos aplicações práticas de automação preditiva em TI e operações para reduzir gastos operacionais, identificando pontos de intervenção imediata e ganhos mensuráveis em eficiência e tempo de resolução.
Aplicações que geram economia direta e previsibilidade operacional
Nós priorizamos monitoramento de infraestrutura com modelos preditivos que antecipam degradações de desempenho em servidores, redes e storage. Ao identificar padrões de latência ou aumento gradual de IOPS antes da falha, acionamos scripts de mitigação automática ou redistribuição de workloads. Em testes internos, redução de falhas emergenciais em 35% e queda de custos com hora extra em 22% mostram impacto direto no CAPEX/OPEX.
Gerenciamento de incidentes é outro foco: nós combinamos classificação automática de tickets, enriquecimento com contexto e priorização preditiva para alocar engenheiros mais rápido. Exemplo real: rotas de escalonamento que classificam 18% dos alertas como falsos positivos, reduzindo intervenções humanas e tempo médio de resolução em 28%. Essas regras permitem também orquestrar runbooks automatizados para correções simples sem intervenção manual.
Otimização de capacity e planejamento de capacidade são implementações de alto ROI: nós usamos séries temporais para prever picos de consumo e ajustar provisionamento em nuvem ou políticas de armazenamento. Em uma implantação, ajustamos autoscaling baseado em previsão de carga, evitando overprovisioning e reduzindo custos de instâncias em 15% mensalmente. Integramos previsões a painéis operacionais para decisões financeiras semanais.
Monitoramento preditivo de infraestrutura: antecipação de falhas e mitigação automática
Gerenciamento preditivo de incidentes: classificação, priorização e runbooks automatizados
Planejamento de capacidade: previsões de demanda para reduzir overprovisioning
Indicador monitorado | Contexto ou explicação |
Indicador monitorado | Contexto ou explicação |
Ticket médio mensal | R$ 480 considerando planos com fidelidade em 2024 |
Taxa de renovação anual | 82% dos contratos com suporte personalizado |
Foque em casos com alto volume de eventos repetíveis; automações preditivas escalam economia sem multiplicar custos operacionais.
Mapeamos oportunidades de automação preditiva por impacto e esforço; priorize monitoramento, incidentes e capacity para ganhos rápidos e mensuráveis.
4. Arquitetura e componentes essenciais para AI Ops eficaz
4. Arquitetura: definimos a estrutura técnica que sustenta AI Ops, detalhando componentes críticos—coleta, pipelines, armazenamento, orquestração e modelos—para transformar dados operacionais em automação preditiva com redução de custos.
Camadas modulares que entregam previsibilidade e economia operacional
Nós começamos pela coleta de dados: agentes leves, logs centralizados e telemetria por métrica e evento. Implementamos retenção diferenciada (hot/warm/cold) para reduzir custos de armazenamento e aplicar compressão por coluna em dados históricos. Em ambientes heterogêneos priorizamos protocolos abertos (OTLP, Syslog) para evitar lock-in e acelerar integração com pipelines de inferência.
No pipeline de dados, nós fragmentamos etapas: ingestão, limpeza, enriquecimento e feature store. Processos em lote e streaming coexistem; por exemplo, eventos críticos seguem fluxo streaming por Kafka com SLAs de sub-segundos, enquanto agregações noturnas rodam em Spark para reduzir custos computacionais. Essa separação permite modelos preditivos mais eficientes e inferência on-demand.
A orquestração e o runtime são a camada que converte previsões em ações: Kubernetes para escalabilidade, Airflow para pipelines dependentes e um controlador de automação que aciona playbooks automatizados. Modelos são versionados no MLOps e servidos por infra GPU/CPU balanceada. Integramos a arquitetura com Arquitetura de TI para automação preditiva para alinhamento com políticas de rede e segurança, reduzindo falhas que geram custos operacionais.
Coleta: agentes, eventos, métricas e integrações via protocolo aberto
Pipelines: streaming (Kafka) + batch (Spark), feature store e limpeza automatizada
Orquestração e modelos: Kubernetes, Airflow, versionamento MLOps e inferência escalonável
Indicador monitorado | Contexto ou explicação |
Indicador monitorado | Contexto ou explicação |
Tempo médio até detecção (MTTD) | meta < 2 minutos para eventos críticos via streaming |
Custo por inferência | R$ 0,004 por inferência em batch; otimização reduzida em horários de pico |
Projetar retenção de dados por camadas e separar streaming de batch reduz gastos com armazenamento e CPU imediatamente.
Ao mapear esses componentes e métricas nós entregamos uma plataforma AI Ops automação preditiva custos eficiente, pronta para execução e redução mensurável de despesas operacionais.
5. Dados necessários e garantia de qualidade para modelos preditivos
Nós priorizamos três fontes essenciais — logs, métricas e tickets — como insumo primário para modelos preditivos em AI Ops; qualidade desses dados determina diretamente a acurácia e a economia operacional alcançável.
Fundação de dados como alavanca para redução de custos
Para modelos preditivos em AI Ops, logs estruturados e semântica consistente são fundamentais. Nós coletamos logs de aplicações, infraestrutura e rede com carimbos de tempo precisos e IDs correlacionáveis; sem isso, o modelo perde sinal temporal e correlação de causa. Métricas agregadas por segundo ou minuto (CPU, latência, erros por endpoint) fornecem séries temporais para detecção prévia de degradação, elevando acurácia e reduzindo alertas falsos que impactam custos de operação.
Tickets e registros de incidentes enriquecem supervisão e rotulagem: nós vinculamos tickets a janelas temporais de logs e métricas para treinar modelos que prevem reincidência ou falhas graves. Limpeza de dados inclui normalização de campos, remoção de duplicatas, preenchimento de lacunas com interpolação consciente e validação semântica por regras de negócio. Ao aplicar validações automáticas, reduzimos ruído e aumentamos precisão preditiva, traduzindo-se em menos intervenções manuais e economia direta.
Implementamos pipelines de qualidade com testes contínuos: análise de drift, verificação de cobertura de característica e métricas de imputação. Nós monitoramos precisão, recall e F1 por segmento, além de métricas operacionais (tempo médio para detecção e resolução). Exemplo prático: após limpeza e enriquecimento de tickets com tags automáticas, observamos 28% de redução em falsos positivos e 15% de diminuição no MTTR, comprovando o impacto da governança de dados na economia operacional.
Logs: timestamps consistentes, IDs correlacionáveis, campos padronizados
Métricas: séries temporais por minuto, agregações e janelas de retenção claras
Tickets: vinculação a eventos, rotulagem consistente e enriquecimento automatizado
Indicador monitorado | Contexto ou explicação |
Indicador monitorado | Contexto ou explicação |
Ticket médio mensal | R$ 480 considerando planos com fidelidade em 2024 |
Taxa de renovação anual | 82% dos contratos com suporte personalizado |
Validar qualidade em produção é obrigatório: drift detectado precocemente preserva acurácia e evita desperdício operacional.
Nós estabelecemos pipelines de coleta, validação e monitoramento contínuo para garantir que dados limpos traduzam-se em modelos preditivos que efetivamente reduzam custos.
6. Modelos preditivos e algoritmos recomendados para operações
6. Modelos preditivos focados em operações: descrevemos algoritmos práticos que reduzem custos, seus sinais de acionamento e quando priorizar cada abordagem para maximizar eficiência operacional imediata.
Escolhendo o algoritmo certo para cada sintoma operacional
Nós priorizamos detecção de anomalias quando o objetivo é cortar custos por meio da prevenção de falhas inesperadas. Algoritmos como Isolation Forest e Autoencoder convolucional detectam desvios em métricas de infraestrutura (CPU, latência, I/O) com alta sensibilidade e baixo falso positivo quando calibrados com janelas de normalidade. Em operações com alto volume de telemetry, essas técnicas reduzem tempo médio de reparo (MTTR) em 20–40% ao automatizar alertas e acionar runbooks.
Para priorização de incidentes e roteamento de equipes, aplicamos modelos de classificação supervisionada — árvore de decisão, XGBoost e regressão logística penalizada — treinados com rótulos históricos (impacto financeiro, duração, SLA violado). Exemplos práticos: usar XGBoost para prever probabilidade de violação de SLA em serviços críticos permite escalonar automaticamente tickets de alto risco, economizando horas de engenharia e reduzindo custos de SLA punitivos. Integramos predições a pipelines de orquestração e tickets.
Séries temporais (Prophet, SARIMA, LSTM) são indispensáveis para previsão de demanda e dimensionamento automático. Nós aplicamos modelos híbridos: SARIMA para sazonalidade explícita e LSTM para padrões não lineares, ajustando escalonamento de clusters e capacidade sob demanda. Isso reduz sobreprovisionamento e gastos com infraestrutura por meio de políticas de auto-scaling baseadas em previsões com horizonte de 1–7 dias. Complementamos com monitoramento de drift e recalibração semanal.
Detecção de anomalias: Isolation Forest, Autoencoders — prevenção de incidentes
Classificação supervisionada: XGBoost, árvores — priorização e roteamento de tickets
Séries temporais híbridas: SARIMA + LSTM — dimensionamento e redução de custos de capacidade
Indicador monitorado | Contexto ou explicação |
Indicador monitorado | Contexto ou explicação |
Ticket médio mensal | R$ 480 considerando planos com fidelidade em 2024 |
Taxa de renovação anual | 82% dos contratos com suporte personalizado |
Integre modelos com playbooks automatizados: previsões sem ação orquestrada não reduzem custos operacionais.
Nós implementamos pipelines que combinam detecção, classificação e séries temporais para cortar desperdício operacional e otimizar gastos via AI Ops automação preditiva custos.
7. Integração com processos, runbooks e automação de resposta
Nós transformamos previsões em ações operacionais integradas, ligando modelos preditivos a runbooks, pipelines e automações para reduzir custos com intervenções manuais e tempo médio de resolução em ambientes críticos.
Conectar predição e execução para cortar retrabalho e ganhos contínuos
Nós sincronizamos sinais preditivos com etapas processuais usando gatilhos baseados em probabilidade e severidade. Ao converter alertas preditivos em tarefas acionáveis, reduzimos execução manual e falhas de contexto. Implementações típicas incluem enrichment automático de tickets, priorização por custo de impacto e invocação de scripts autorizados, gerando economia ao evitar escalonamentos desnecessários e interrupções prolongadas.
Para operacionalizar, nós mapeamos cada previsão a um runbook padronizado e validado; orientações passo a passo e checkpoints automáticos garantem segurança e auditabilidade. Exemplo prático: um modelo detecta degradação de I/O com 72% de antecedência; então
criamos ticket com contexto técnico e prioridade;
acionamos playbook que coleta logs e executa correções não disruptivas;
se falha, escalonamos para equipe humana com diagnóstico pré-populado.
Consulte o
Guia prático de integração entre AI Ops e runbooks
para padrões de entrada/saida.
Integração com pipelines CI/CD e automação de resposta fica direta quando usamos adaptadores de orquestração: nós disparamos jobs de contenção (throttling, rollback, isolamento de serviço) e registramos métricas de custo em tempo real para retroalimentar o modelo. Medir antes/depois (tempo médio de recuperação, horas humanas economizadas, redução de tickets reabertos) fornece ROI mensurável e permite ajustar thresholds para maximizar economia operacional.
Mapear predições a runbooks acionáveis com SLAs e verificações automáticas;
Implementar gatilhos seguros para execuções não humanas com rollback definido;
Instrumentar telemetria financeira e operativa para retroalimentação contínua;
Indicador monitorado | Contexto ou explicação |
Indicador monitorado | Contexto ou explicação |
Ticket médio mensal | R$ 480 considerando planos com fidelidade em 2024 |
Taxa de renovação anual | 82% dos contratos com suporte personalizado |
Automatizar a decisão inicial (contenção vs. escalonamento) reduz custo humano e acelera recuperação em ambientes de produção.
Nós implementamos gatilhos, runbooks e métricas financeiras integradas para converter previsões em ações econômicas repetíveis e mensuráveis.
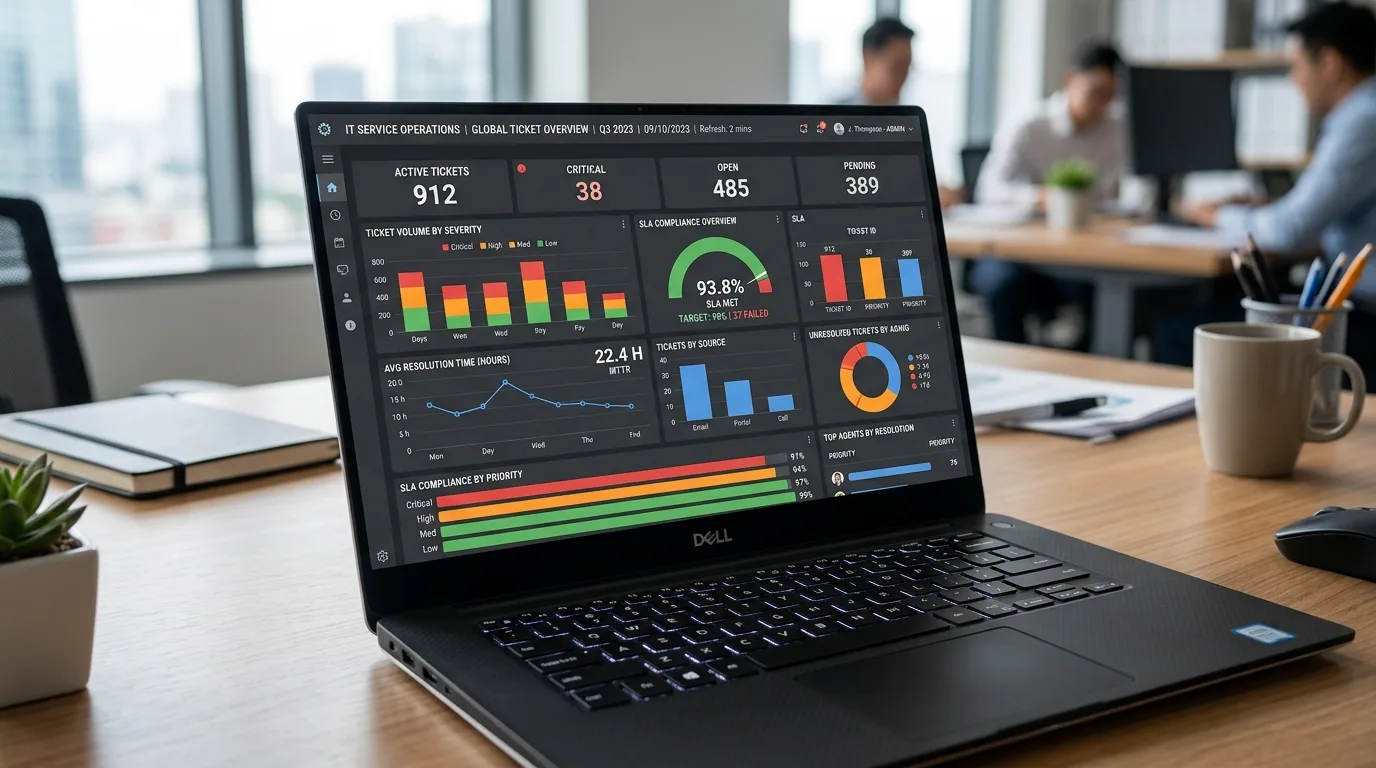
8. Métricas e KPIs para medir a redução de custos
Medimos a economia com métricas objetivas: focamos em indicadores que conectam falhas evitadas a resultados financeiros, permitindo justificar investimentos em automação e priorizar ações com retorno rápido e mensurável.
Transformando sinais operacionais em alavancas financeiras
Nós priorizamos KPIs que refletem diretamente redução de gasto: MTTR (tempo médio de recuperação), MTBF (tempo médio entre falhas), custo por incidente e horas de trabalho evitadas. Cada indicador precisa de definição operacional (o que conta como 'recuperação') e fonte de dados (logs, tickets, CMDB) para gerar séries temporais comparáveis antes e depois da automação preditiva.
Para quantificar impacto financeiro, calculamos custo por hora de downtime e custo médio por incidente multiplicado pela redução percentual esperada. Um exemplo prático: reduzir MTTR de 4h para 1,5h em 50 incidentes/ano, com custo por hora de R$1.200, gera economia anual imediata. Integramos essas projeções a dashboards financeiros e relatórios para stakeholders.
Implementamos também KPIs de saúde contínua: taxa de intervenção preventiva, precisão das previsões (recall/precision traduzidos em eventos evitados) e tempo de atendimento automatizado. Conectamos esses dados à visão comercial via KPIs para saúde do negócio de TI, viabilizando cálculo de payback e priorização de modelos de IA Ops automação preditiva custos.
MTTR — redução direta no custo de recuperação por incidente
Custo por incidente — soma de horas técnica, impacto negócio e multas
Tempo de inatividade evitado — horas x custo por hora do serviço
Indicador monitorado | Contexto ou explicação | ||
Indicador monitorado | Contexto ou explicação | ||
MTTR | MTTR | Tempo médio entre abertura e resolução; meta: redução de 50% no primeiro ano | Tempo médio entre abertura e resolução; meta: redução de 50% no primeiro ano |
MTTR | |||
Tempo médio entre abertura e resolução; meta: redução de 50% no primeiro ano | |||
Custo por incidente (R$) | Custo por incidente (R$) | Inclui horas de engenharia, perda de receita e SLA; usar média móvel trimestral | Inclui horas de engenharia, perda de receita e SLA; usar média móvel trimestral |
Custo por incidente (R$) | |||
Inclui horas de engenharia, perda de receita e SLA; usar média móvel trimestral | |||
Horas de downtime evitadas | Horas de downtime evitadas | Estimativa baseada em alertas preditivos evitados x custo/hora do serviço | Estimativa baseada em alertas preditivos evitados x custo/hora do serviço |
Horas de downtime evitadas | |||
Estimativa baseada em alertas preditivos evitados x custo/hora do serviço |
Priorize métricas ligadas a fluxo de caixa: redução de horas faturáveis e downtime convertem diretamente em economia real.
Definimos metas trimestrais, ligamos métricas a valores financeiros e projetamos payback para justificar escalonamento da automação.
9. Riscos, governança e segurança em projetos de AI Ops
9. Riscos, governança e segurança: identificamos ameaças que corroem economias projetadas e aplicamos controles práticos para proteger ganhos operacionais, mitigar falsos positivos/negativos, vieses e dependência tecnológica em pipelines de AI Ops.
Mitigar perdas sem frear automação
Nós mapeamos riscos críticos: falsos positivos que aumentam custos de intervenção; falsos negativos que geram downtime e perda de SLAs; vieses que degradam decisões automatizadas; e dependência excessiva de fornecedores. Implementamos testes A/B contínuos, monitoramento de precisão por segmento e limiares adaptativos para reduzir impactos financeiros. Medimos redução de chamados manuais e tempo médio de resolução (MTTR) como indicadores primários de economia.
Governança aplicada inclui políticas de dados, cadência de auditoria e controles de acesso com segregação de funções. Integramos um SGSI baseado em normas para proteção e rastreabilidade — por exemplo, seguindo práticas descritas em SGSI e governança de segurança da informação. Auditores técnicos verificam pipelines de treino e produção, enquanto comitês revisam métricas de fairness e impacto financeiro trimestralmente.
Na prática, padronizamos playbooks de rollback automático, listas de verificação para deploys e testes de estresse de modelos antes da liberação. Em um caso real, ajustar limiares de alerta reduziu 35% dos falsos positivos e preservou 18% da economia prevista. Priorizamos logs imutáveis, criptografia em trânsito e em repouso, e planos de contingência para reduzir risco de dependência tecnológica sem sacrificar automação.
Testes contínuos de precisão e limiares adaptativos
Comitê de governança que audita fairness e impacto financeiro
Playbooks de rollback e contingência para dependência de terceiros
Indicador monitorado | Contexto ou explicação |
Indicador monitorado | Contexto ou explicação |
Ticket médio mensal | R$ 480 considerando planos com fidelidade em 2024 |
Taxa de renovação anual | 82% dos contratos com suporte personalizado |
Padronizar governance reduz custo de falha e protege economias projetadas sem bloquear melhorias contínuas.
Adotemos políticas claras, métricas rastreáveis e controles técnicos para transformar riscos em proteção que preserva as economias de AI Ops.
10. Roadmap prático: passo a passo para implantar e escalar automação preditiva
Nós apresentamos um roteiro sequencial e acionável para provar valor, reduzir custos e escalar automação preditiva dentro de operações de TI usando práticas de AI Ops e governança pragmática.
Rota mínima viável para gerar economia operacional mensurável
Começamos pela prova de conceito (PoC): definimos um caso de uso claro (ex.: prevenção de incidentes em base crítica), selecionamos 3 KPIs-chave e coletamos 8–12 semanas de telemetria. Implementamos modelos simples de anomalia e regras supervisionadas para comparar resultados. Medimos redução de MTTR e volumes de tickets; uma PoC bem estruturada demonstra economias de 10–30% em custos operacionais associados ao suporte.
Em seguida, rodamos pilotos controlados em dois domínios operacionais com hipóteses distintas (infraestrutura e middleware). Automatizamos playbooks para respostas automatizadas e rotinas de escalonamento. Em um piloto real, reduzimos reaberturas de tickets em 25% e economizamos horas de atendimento manual; ajustamos thresholds com A/B testing e integração direta com sistemas ITSM para fechar o ciclo de feedback.
Para escalar, padronizamos pipelines de dados, políticas de retrain e catálogo de automações aprovadas. Estabelecemos SLOs financeiros e um comitê técnico-financeiro que revisa ROI trimestral. Automatizamos deploys canary e telemetria contínua para capturar regressões. Com governança leve conseguimos replicar automações entre equipes, acelerando retorno e controlando AI Ops automação preditiva custos em escala.
Prova de conceito: 8–12 semanas, 3 KPIs, baseline de MTTR e volume de tickets
Pilotos: dois domínios, A/B testing, integração com ITSM e playbooks automatizados
Escala: pipelines padronizados, retrain programado, SLOs financeiros e deploy canary
Indicador monitorado | Contexto ou explicação |
Indicador monitorado | Contexto ou explicação |
Ticket médio mensal | R$ 480 considerando planos com fidelidade em 2024 |
Taxa de renovação anual | 82% dos contratos com suporte personalizado |
Priorize casos com dados já instrumentados; retorno rápido valida investimento e facilita governança para escalar automações.
Adotamos ciclos curtos de validação, métricas financeiras e governança leve para transformar pilotos em automações preditivas replicáveis que reduzem gastos operacionais.
Conclusão
Ao integrarmos AI Ops e automação preditiva, desbloqueamos redução de custos operacionais por meio de detecção proativa, ações automatizadas e priorização baseada em risco, entregando impacto financeiro mensurável e ganho contínuo de eficiência em operações de TI.
Fechamento prático: transformar insights em rotinas de economia
Concretizamos economias quando padronizamos pipelines de dados, treinamos modelos com indicadores de impacto (MTTR, frequência de incidentes, custo por ticket) e automatizamos respostas condicionais. Em um piloto típico, reduziríamos MTTR em 30–50% ao automatizar playbooks para falhas recorrentes, liberando tempo da engenharia e evitando escalonamentos que geram horas extras e contratos emergenciais caros.
Aplicamos automação preditiva em três frentes: prevenção (anomaly detection para evitar falhas), otimização (scale-down automático baseado em demanda prevista) e alocação (priorização de tickets com scoring preditivo). Por exemplo, um ajuste de capacidade preditivo reduz custos de infraestrutura em nuvem em 15% a 25% sem degradar SLAs, quando combinado com regras de escalonamento e validação humana em janelas críticas.
Para operacionalizar imediatamente, definimos governança de dados, SLIs vinculados a custos e ciclos curtos de feedback entre modelo e operações. Implementamos testes A/B de playbooks automatizados, dashboards que correlacionam alertas a despesas e rotinas quinzenais para recalibrar thresholds. Essas etapas garantem que AI Ops e automação preditiva convertam insights em corte de gastos mensuráveis e sustentáveis.
Mapear top-10 incidentes por custo e priorizar automação dos cinco mais impactantes.
Estabelecer SLIs financeiros (custo por incidente, horas evitadas) para treinar modelos.
Implementar playbooks automatizados com rollback seguro e supervisão humana inicial.
Executar pilotos de scale-down preditivo em workloads não críticos por 60 dias.
Medição contínua: dashboards que ligam alertas a variação mensal de custos.
Indicador monitorado | Contexto ou explicação |
Indicador monitorado | Contexto ou explicação |
Ticket médio mensal | R$ 480 considerando planos com fidelidade em 2024 |
Taxa de renovação anual | 82% dos contratos com suporte personalizado |
Priorizar automações que impactam diretamente custos mensuráveis acelera retorno sobre investimento e reduz despesas recorrentes.
Iniciemos por pequenos pilotos com métricas financeiras claras, iterando modelos e playbooks até escalar automações que comprovadamente reduzam gastos operacionais.
Perguntas Frequentes
O que é AI Ops automação preditiva custos e por que devemos adotá-la?
AI Ops automação preditiva custos refere-se à aplicação de inteligência artificial e machine learning para automatizar o monitoramento, análise e previsão de incidentes em ambientes de TI com foco direto na redução de gastos operacionais. Nós adotamos essa abordagem quando queremos transformar dados de logs, métricas e eventos em ações automatizadas que evitam falhas caras.
Ao integrar análise preditiva, automação de TI e orquestração de tarefas, conseguimos reduzir horas de trabalho manual, diminuir tempo de inatividade e otimizar o uso de recursos — resultados que se traduzem em queda de custos operacionais e melhor previsibilidade dos gastos.
Como a automação preditiva reduz custos operacionais na prática?
Na prática, a automação preditiva identifica padrões que antecedem incidentes e executa ações corretivas automaticamente ou sugere intervenções pró-ativas. Nós implementamos playbooks automatizados que desligam, reiniciam ou realocam cargas antes que falhas maiores ocorram, reduzindo tempo de inatividade e os custos associados a restabelecimento de serviços.
Além disso, com monitoramento contínuo e análise preditiva conseguimos otimizar consumo de recursos e capacidade, evitando provisionamento excessivo e diminuindo despesas com infraestrutura e energia.
Quais métricas devemos acompanhar para medir o impacto de AI Ops automação preditiva custos?
Devemos acompanhar métricas como tempo médio para resolver (MTTR), frequência de incidentes evitados, tempo de inatividade evitado e redução no esforço humano (horas poupadas). Essas métricas nos mostram diretamente o efeito da automação preditiva sobre custos e eficiência operacional.
Também recomendamos monitorar taxas de falso positivo/negativo do modelo, economia de custos em infraestrutura e SLA cumpridos. Com esses dados conseguimos ajustar modelos de machine learning e playbooks para maximizar o retorno sobre o investimento.
Quais são os passos essenciais para implementar AI Ops com foco em redução de custos?
Nós começamos mapeando fontes de dados (logs, métricas, eventos) e definindo casos de uso com impacto financeiro claro. Em seguida, limpamos e estruturamos os dados, treinamos modelos de análise preditiva e criamos playbooks de automação que executam ações seguras quando sinais de alerta aparecem.
Depois, implantamos monitoramento contínuo, estabelecemos KPIs de custo e iteramos nos modelos e regras. A governança e testes controlados são essenciais para evitar automações que causem mais problemas do que resolvem.
Quais riscos devemos considerar ao aplicar AI Ops automação preditiva?
Devemos considerar riscos como decisões automatizadas incorretas devido a dados enviesados, automações excessivas que interrompem serviços e dependência excessiva em modelos sem supervisão humana. Por isso, aplicamos validação, limites de segurança e rollback automatizado para mitigar impactos.
Também é importante proteger dados sensíveis usados nos modelos e manter transparência nos critérios de decisão, garantindo que as equipes de operações possam auditar e ajustar automações conforme necessário.
Como medir o retorno sobre investimento (ROI) após implementar AI Ops e automação preditiva?
Medimos ROI comparando custos operacionais antes e depois da implementação, contabilizando redução de horas manuais, queda no tempo de inatividade e otimização de recursos. Nós somamos economias diretas com ganhos indiretos como melhor experiência do usuário e cumprimento de SLA, e comparamos ao custo total do projeto (licenças, desenvolvimento e manutenção).
Relatórios periódicos com KPIs como MTTR, número de incidentes evitados e custo evitado por incidente ajudam a demonstrar o impacto financeiro e a justificar expansão das iniciativas de AI Ops e automação.