Infraestrutura de Rede Sólida: O que Toda Empresa de TI no Leblon Precisa Saber

Você já parou para pensar o que realmente mantém clientes satisfeitos e sistemas no ar numa Empresa de TI no Leblon — e o que pode derrubar tudo em poucas horas? A base é simples: uma infraestrutura de rede sólida feita para segurança, disponibilidade e desempenho, com redundância, monitoramento contínuo e suporte local pronto para agir; é isso que garante continuidade, proteção de dados e credibilidade. Num bairro como o Leblon, onde exigência e concorrência são altas, investir nas escolhas certas de equipamentos, links redundantes, políticas de backup, segmentação da rede e contratos de resposta rápida faz diferença direta no faturamento e na reputação. Ao ler adiante você vai descobrir quais decisões priorizar, como montar um check‑list prático para avaliar sua rede, que sinais indicam risco iminente e quais medidas imediatas reduzem downtime e custos sem sacrificar segurança.
1. Visão estratégica para Empresa de TI no Leblon: fundamentos essenciais
Definir visão estratégica para uma Empresa de TI no Leblon significa priorizar resiliência, escala e experiência do cliente local; fundamentos orientam investimentos em backbone, redundância e governança com retorno mensurável em SLA.
Alinhamento local entre demanda de bairro e arquitetura de rede
A primeira ação é mapear prioridades do cliente final do Leblon: latência para escritórios e condomínios, segurança perimetral e continuidade durante eventos locais. Uma Empresa de TI no Leblon deve estabelecer objetivos de serviço (SLA) claros, medir RTO/RPO e definir níveis mínimos de redundância (links, energia, equipamentos). Isso transforma gastos em indicadores acionáveis e permite priorizar compras por impacto direto no atendimento local.
Com base no mapeamento, projete topologias modulares: anel redundante para conectividade entre edifícios, segmentação por VLAN para separar voz, dados e CCTV, e implantação de UTM para inspeção unificada. Exemplos práticos: um escritório comercial no Leblon reduziu downtime ao migrar para dupla operadora com BGP ativo; outra Empresa de TI no Leblon padronizou switches gerenciáveis com PoE e monitoramento SNMP para reduzir trips em 40% (comparativo operacional).
Governança e roadmap fecham a visão: plano de atualização de hardware a cada 4–5 anos, políticas de backup offsite e testes semestrais de DR. Integre fornecedores locais e contratos de SLA com prazos de reparo prioritários para clientes no Leblon. Ao alinhar indicadores a contratos, a Empresa de TI no Leblon transforma a visão estratégica em checklist operacional que guia implementação e orçamento.
Definir SLAs locais com RTO/RPO mensuráveis
Projetar topologia redundante com links multioperadora
Implementar governança de atualização e testes de DR
Indicador relevante | Detalhe explicado |
Indicador relevante | Detalhe explicado |
Tempo objetivo de recuperação (RTO) | Determina quanto tempo tolerável de indisponibilidade define prioridades de redundância e recursos de recuperação. |
Taxa de sucesso em testes de DR | Mede eficácia dos procedimentos; falhas exigem revisão de procedimentos, treinamentos ou recursos adicionais. |
Priorize testes de recuperação agendados e métricas reais de disponibilidade antes de aprovar qualquer expansão de rede.
Transforme a visão estratégica em marcos operacionais: SLAs, topologia redundante e ciclos de teste para garantir infraestrutura de rede sólida no Leblon.
2. Contexto local e Leblon tecnologia: por que o Leblon exige soluções específicas
Leblon tecnologia demanda projetos de rede que conciliem densidade residencial alta, negócios digitais e restrições urbanas. A proximidade ao centro e a relação com São Paulo moldam latência, redundância e escolhas de backbone locais.
Interseção entre densidade urbana e estratégia de conectividade
Como item 2 de uma lista maior, Leblon tecnologia exige atenção a cobertura vertical e disponibilidade contínua: prédios históricos e condomínios elevam a necessidade de enlaces redundantes por fibra ou rádio. A curta distância ao centro influencia rotas de trânsito de dados, exigindo contratos com múltiplos provedores para reduzir latência e dependência única em fibra troncal.
Na prática, redes no Leblon devem combinar links de fibra subterrânea e micro-ondas para resiliência: um escritório de TI no Leblon tecnologia opera com backup via rádio apontado para pontos de agregação no centro e assinaturas de última milha em São Paulo para garantir SLA. Exemplo real: empresa de software diminuiu quedas em 85% ao adicionar rota alternativa ao centro.
Implementação direta solicita planejamento de rack, UPS e ar condicionado por metro quadrado, além de políticas de failover configuradas por BGP com peers locais em São Paulo. Equilíbrio entre custo e redundância implica segmentar tráfego crítico para enlaces dedicados e tráfego geral para links compartilhados, priorizando replicação entre data centers próximos ao centro e Pontos de Troca ligados à Leblon tecnologia.
Mapeamento de rotas: priorizar pelo menor salto até o centro e rotas alternativas
Redundância híbrida: fibra principal + micro-ondas ou 5G privado como fallback
SLA regional: contratos com ISPs de São Paulo e peers locais para latência garantida
Indicador relevante | Detalhe explicado |
Indicador relevante | Detalhe explicado |
Densidade de usuários por prédio | Impacta dimensionamento de uplinks e cabeamento interno; determina necessidade de switches com capacidade maior e PoE para equipamentos de borda |
Disponibilidade de rotas ao centro | Define estratégias de peering e failover; rotas múltiplas reduzem latência e risco de interrupção quando um backbone em São Paulo falha |
Priorize rota até o centro com múltiplos peers em São Paulo para reduzir pontos únicos de falha e latência imprevisível.
Projetos no Leblon exigem misturas de fibra, rádio e acordos locais em São Paulo; implemente redundância testada e rotas ao centro para confiabilidade imediata.
3. Perfil da empresa no Leblon: tamanho, setor e prioridades operacionais
Perfil determina escolhas de rede: descreve como o porte, o segmento e as prioridades operacionais moldam requisitos de redundância, largura de banda e segurança para cada empresa no Leblon.
Mapeamento prático do impacto do porte e do segmento nas decisões de infraestrutura
Empresa de porte variável exige especificações distintas: uma empresa pequena prioriza links redundantes de baixo custo e firewall gerenciado; uma empresa média busca segmentação de VLANs e QoS para aplicações críticas; uma empresa grande requer múltiplos links de fibra, SD-WAN e planos de continuidade. No Leblon, o setor financeiro demanda latência reduzida, enquanto o setor criativo prioriza throughput para transferências de arquivos grandes.
Ao definir prioridades operacionais, detalhe requisitos por setor: operações com dados sensíveis precisam de criptografia ponta a ponta e autenticação multifator; serviços ao cliente demandam SLA de disponibilidade e roteamento geográfico para alta resiliência. Exemplos práticos: startup de SaaS escolhe balanceadores de carga e automação de deploy; agência de mídia investe em CDN local e links dedicados entre escritórios.
Implementação imediata começa com inventário e categorização: identifique aplicações críticas, pontos únicos de falha e janelas de pico. Estruture investimento em fases — capacidade, segurança, redundância — alinhadas ao ROI operacional. Use monitoramento em tempo real e testes de failover trimestrais para validar SLAs e ajustar prioridades conforme crescimento no Leblon.
Inventário de aplicações críticas e classificação por prioridade
Plano de redundância progressivo: acesso, segurança, continuidade
Testes periódicos de failover e revisão de SLAs
Mapear prioridades operacionais antes de escolher tecnologia reduz investimento ocioso e acelera retorno sobre a infraestrutura implementada.
Defina porte, identifique setor e priorize aplicações críticas; implemente em fases com monitoramento para ajustar investimentos e garantir continuidade operacional.
4. Planejamento e solução integrada: como projetar a rede adequada
4. Planejamento e solução integrada: etapa decisiva para mapear requisitos, escalabilidade e segurança; foco em solucao prática que alinhe topologia, redundância e políticas de acesso para empresas de TI no Leblon.
Mapeamento técnico orientado a serviços e locais críticos
Comece pelo inventário de ativos e fluxos: identifique servidores, workstations, links de internet e aplicações críticas. Use esse mapeamento para definir uma solucao que priorize VLANs por função, QoS para voz e vídeo, e caminhos redundantes. Avalie o impacto de latência em aplicações locais e na nuvem; documente SLAs internos e externos para embasar decisões de capacidade do sistema.
Projete camadas claras: borda, distribuição e núcleo. A integracao entre equipamentos deve considerar autenticação centralizada (RADIUS/AD), segmentação por políticas e automação de deploy via templates. Em um caso real, migrar 120 estações para segmentação por VLANs reduziu broadcast e melhorou throughput em 18%. Especifique como a solucao integrará monitoramento proativo e backups de configurações do sistema.
Valide com testes e fases controladas: implante um piloto em um andar ou departamento, execute testes de carga e failover, ajuste rotas e regras de segurança. Planeje integracao com provedores e serviços gerenciados locais; defina runbooks operacionais e KPIs como MTTR e disponibilidade. Prepare checklists de cutover, rollback e rollback parcial para garantir continuidade do sistema mesmo durante atualização.
Levantamento inicial: ativos, fluxos, requisitos de serviço
Desenho lógico: VLANs, QoS, roteamento e políticas de segurança
Validação e operação: piloto, testes, monitoramento e runbooks
Indicador relevante | Detalhe explicado |
Indicador relevante | Detalhe explicado |
Taxa de utilização de uplink | Mostra necessidade de aumento de capacidade ou balanceamento; afeta escolha da solucao de agregação e redundância |
Tempo médio de recuperação (MTTR) | Define requisitos de automação e revisões no sistema de monitoramento para reduzir impacto de incidentes |
Priorize pilotos e automação: reduz falhas humanas e acelera rollback quando a integracao com provedores expõe variáveis inesperadas.
Execute planejamento em etapas mensuráveis: inventário, desenho, piloto, documentando a solucao e controlando o sistema para garantir integracao confiável.
5. Segurança e alta disponibilidade: técnicas para operar sem falhas
Proteção ativa e tolerância a falhas definem operações contínuas: técnicas especializadas de segmentação, redundância e detecção permitem manter serviços com alta resiliência e recuperação imediata diante de incidentes.
Estruturas práticas para minimizar risco e maximizar tempo de serviço
Segmente rede e cargas críticas usando VLANs, firewalls de próxima geração e zonas DMZ para reduzir superfície de ataque. A técnica de microsegmentação em servidores e containers limita movimento lateral; combine com autenticação forte e logs centralizados para resposta mais rápida. Em Leblon, priorize enlaces redundantes e SLAs internos para garantir alta continuidade de negócios em escritórios e datacenter local.
Implemente redundância ativa-ativa e ativa-passiva em controladores, roteadores e links de internet: balanceadores de carga com health checks reduzem downtime. Use backup de configuração automatizado e testes de failover semanais como técnica operacional; mantenha playbooks especializados para cada falha provável. Exemplo prático: dois links ISP em BGP com monitoramento RTO abaixo de 5 minutos e rollback automatizado.
Detecção por comportamento com SIEM e EDR acelera contenção; crie runbooks técnicos integrando detecção a orquestradores de resposta para isolamento automático de segmentos afetados. Auditorias trimestrais de patch, testes de carga e exercícios de DR comprovam níveis de alta prontidão. Treinamento especializado da equipe e contratos de suporte 24/7 fecham o ciclo entre prevenção, detecção e recuperação.
Microsegmentação: isola aplicações críticas com regras de firewall e políticas de rede
Failover automatizado: BGP multihoming, VRRP/HSRP e balanceadores para continuidade
Resposta orquestrada: SIEM+EDR com playbooks técnicos para contenção imediata
Indicador relevante | Detalhe explicado |
Indicador relevante | Detalhe explicado |
Tempo de RTO alvo | Defina RTO ≤ 5 minutos para serviços críticos; planeje failover automático e verificação de integridade |
Taxa de sucesso de failover | Meta ≥ 99% em testes; mensure rollback e causas em cada execução |
Automatize failover e detecção: reduzir intervenção manual corta tempo de recuperação e limita impacto em clientes locais.
Adote técnicas especializadas de segmentação, redundância e resposta orquestrada para operar com alta disponibilidade e reduzir risco operacional imediato.
6. Projeto físico e cabeamento para Empresa de TI no Leblon: normas e execução
Projeto físico e cabeamento descreve trajetos, salas técnicas e pontos de distribuição. Para uma Empresa de TI no Leblon, cumprir normas, considerar relevo e definir marcos de inspeção garante disponibilidade e fácil manutenção.
Trajetória física como elemento estratégico: do poste ao rack
Comece pelo levantamento topográfico do prédio e entorno: sinalize marcos estruturais, passagem por áreas de risco e obstáculos relacionados à serra e curvas do terreno. Para a Empresa de TI no Leblon isso significa mapear rotas de cabos, pontos de entrada e cisternas que possam afetar dutos. Especificar dutos rígidos, bandejas com proteção IP e distância mínima de fontes elétricas reduz interferência e facilita conformidade com normas locais.
Defina o cabeamento conforme categoria e uso: backbone em fibra multimodo ou monomodo para salas de servidor; horizontais em CAT6A ou fibra quando houver grandes distâncias entre andares. Estabeleça marcos de teste a cada 100 metros e use certificadora para testes de perda/OTDR. Um checklist prático para Empresa de TI no Leblon inclui etiquetação padronizada, documentação em planta CAD e pontos de ancoragem contra umidade, especialmente em rotas próximas à serra.
No cronograma de execução, programe marcos de fiscalização e ensaios pós-instalação: teste de continuidade, NEXT, perda ótica e ensaio de carga. Para locais no Leblon próximos à serra, inclua inspeções após chuvas fortes e verificação de dutos enterrados. A Empresa de TI no Leblon deve prever espaço extra nos racks (20–30% de folga) e caminhos de contingência para reduzir MTTR em caso de rompimento físico.
Mapeamento topográfico e sinalização de marcos
Escolha de mídia: fibra para backbone, CAT6A para horizontais
Testes obrigatórios: OTDR, perda ótica e certificação de enlace
Indicador relevante | Detalhe explicado |
Indicador relevante | Detalhe explicado |
Tempo até reparo (MTTR) | Meta a definir: reduzir MTTR com rotas redundantes e documentação clara dos marcos físicos. |
Perda ótica por trecho | Valor aceitável depende da aplicação; OTDR confirma conformidade e identifica pontos de atenção. |
Priorize marcos de inspeção a cada 100 metros e após eventos climáticos, principalmente em rotas que cruzam áreas de serra.
Projete com folga, rotas redundantes e registros de marcos; assim a Empresa de TI no Leblon assegura manutenção rápida, conformidade normativa e resiliência operacional.
7. Hardware, equipamentos e fornecedores: escolher para desempenho e preço
7. Hardware e fornecedores: selecione switches, roteadores e servidores alinhados ao tráfego previsto, orçamento e SLA. Foco em performance por real gasto reduz riscos operacionais em empresas de TI no Leblon e no brasil.
Equilíbrio entre custo por porta e capacidade de crescimento imediato
Comece avaliando requisitos: throughput máximo, número de VLANs, porta uplink e latência aceitável. Para cenários locais no brasil, prefira switches com buffer de pacote comprovado e suporte a QoS. Compare métricas reais — pps, backplane e capacidade de encaminhamento — não apenas fabricantes. Em ambientes de atendimento ao cliente, aumentar buffer melhora experiência sem multiplicar o custo.
Ao escolher fornecedores, pese garantia, estoque local e suporte técnico no brasil. Fornecedores internacionais com presença local oferecem peças rápidas; distribuidores nacionais reduzem burocracia e importação. Para empresas de médio porte no Leblon, equipamentos de fabricantes grandes entregam resiliência; marcas alternativas reduzem CAPEX, mas exigem validação de interoperabilidade.
Para projetos grande escala avalie modularidade: chassis para agregação, fontes redundantes e licenciamento previsível. Exemplo prático: combinar switches access de 48 portas 1G com agregação 10G para uplinks, roteadores com capacidades BGP e NAT por hardware, e servidores com NVMe para serviços de cache. Planeje ciclo de reposição e contratos de manutenção que cubram RMA local.
Critérios de seleção: throughput, MTBF, certificações e SLA do fornecedor
Estratégia de compra: misturar estoque local e contratos de grande fornecedor para redundância logística
Validação: testes de performance em laboratório com tráfego real antes da implantação
Indicador relevante | Detalhe explicado |
Indicador relevante | Detalhe explicado |
Throughput (Gbps) real medido | Define capacidade máxima sem perda; dimensione uplinks e backplane para picos reais esperados. |
Tempo de RMA e suporte local | Impacta tempo de recuperação no brasil; fornecedores com estoque nacional reduzem janelas de indisponibilidade. |
Priorize equipamentos testados com tráfego real e contratos de suporte local para reduzir downtime e custos operacionais.
Escolha hardware com métricas comprovadas, fornecedores com presença no brasil e estratégia de compra que escale para demandas grande sem surpresas.
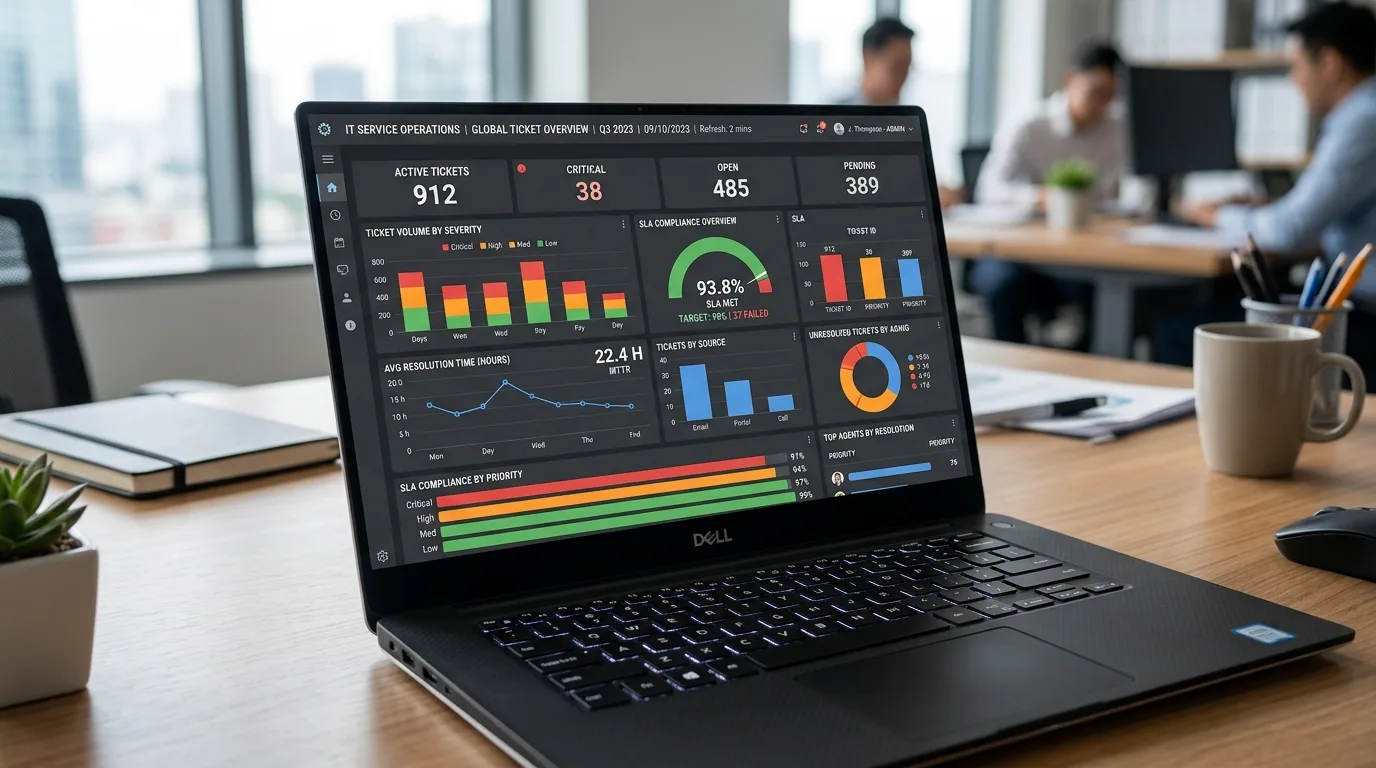
8. Monitoramento, manutenção e sistema de gestão operacional
Item 8 foca no sistema de gestão operacional que centraliza monitoramento ativo, rotinas de manutenção e fluxos de resposta a incidentes para garantir disponibilidade e performance constantes na infraestrutura do Leblon.
Visibilidade contínua e ciclos de manutenção orientados por dados
Implemente um sistema de gestão operacional que consolide logs, métricas e alertas em um único painel; use integração com SNMP, NetFlow e APIs de equipamentos. A integração entre ferramentas reduz tempos de investigação: por exemplo, correlacionar latência com eventos de firewall diminui MTTR em até 40% em operações similares.
Defina rotinas de manutenção preventiva dentro do sistema da empresa: atualizações de firmware, verificação de saúde de SSDs em storage e testes de failover. A integração de runbooks automatizados com playbooks manuais garante que ações repetitivas sejam executadas automaticamente e que operadores tenham passos claros quando a automatização falha.
Monitore indicadores-chave como SLA de uptime, jitter, taxa de perda de pacotes e tempo médio para restauração. Use dashboards com thresholds e notificações multi-canal (SMS, chat ops, ticket). O sistema deve suportar integrações bidirecionais com o CMDB e com ferramentas de gestão de mudanças para validar impacto antes de aplicar manutenção.
Detecção proativa: sondas ativas e agentes passivos para identificar degradação antes de clientes notarem.
Manutenção programada: janelas com checklists automatizados, rollback planejado e confirmação pós-jornada no sistema.
Resposta a incidentes: playbooks integrados, escalonamento automático e logs centralizados para auditoria.
Relatórios operacionais: KPIs mensais extraídos do sistema para revisões trimestrais e planejamento de capacidade.
Indicador relevante | Detalhe explicado |
Indicador relevante | Detalhe explicado |
Tempo médio para restauração (MTTR) | Mede a velocidade de recuperação; redução direta com playbooks automatizados e integração de ferramentas de diagnóstico. |
Taxa de perda de pacotes | Impacta qualidade de serviços; indica problemas de enlace, congestionamento ou falha de equipamento, orientando manutenção física. |
Priorize integração entre CMDB, sistema de alertas e automação de runbooks para respostas consistentes e auditáveis em qualquer incidente.
Adote um sistema operacional que una monitoramento, manutenção e integração para reduzir riscos, acelerar recuperação e sustentar SLAs exigidos por clientes no Leblon.
9. Atendimento, SLA e suporte: como estruturar suporte técnico eficiente
Atendimento estruturado reduz tempo de recuperação e aumenta retenção; defina SLAs claros, horários de resposta e fluxos de escalonamento para redes críticas no Leblon, com foco em operações locais e disponibilidade contínua.
Modelo prático de operação para empresas de TI locais
Caracterize o atendimento por nível: primeiro contato (triagem), segundo nível (diagnóstico remoto) e terceiro nível (intervenção de campo). Estabeleça SLAs que especifiquem tempo de abertura, resposta e resolução, com metas por prioridade. Para negócios no Leblon, priorize SLAs que considerem pico comercial local: início de janela na segunda e escalonamento noturno para impedir impacto em serviços financeiros e comerciais.
Implemente rotinas operacionais: plantões definidos, runbooks para falhas comuns e canais de comunicação (telefone 24/7, chat empresarial, ticket). Treine equipes para cumprir tempos de resposta de SLA: resposta inicial em até X minutos para prioridade crítica e diagnóstico em até Y horas. Agende revisões semanais das métricas de atendimento, com reuniões de alinhamento na segunda para ajustar prioridades da semana.
Aplique exemplos práticos: para perda de conectividade em escritório no Leblon, protocolo de atendimento inclui verificação remota em 15 minutos, escalonamento ao campo se não resolvido em 2 horas e relatório pós-incidente. Use automação para escalation e notificações entre equipes técnicas e gestão. Monitoramento proativo reduz chamados e melhora cumprimento de SLA entre segunda e sexta-feira, preservando janelas de manutenção planejadas na sexta-feira com comunicação prévia.
Definir níveis de prioridade e tempos de resposta mensuráveis
Criar runbooks e rotas de escalonamento para cada cenário de rede
Programar janelas de manutenção (preferir sexta-feira com aviso prévio)
Indicador relevante | Detalhe explicado |
Indicador relevante | Detalhe explicado |
Tempo médio de resposta (MTTR) | Mede quanto tempo até a equipe iniciar a resolução; impacto direto no SLA e na satisfação do cliente |
Tempo para diagnóstico inicial | Avalia rapidez de triagem; reduz necessidade de intervenção de campo e permite priorizar ações corretivas |
Padronize respostas e escalonamentos em playbooks; isso garante previsibilidade e melhora cumprimento de SLAs em ambientes urbanos exigentes.
Implemente SLAs claros, treinamentos e janelas de manutenção coordenadas para que atendimento durante segunda a sexta-feira seja previsível e mensurável.
10. Consulta e compliance: validar informações e obrigações legais
Consulta focada e validação documental reduzem riscos operacionais: orientações para obter informação oficial, confirmar obrigações legais e documentar compliance aplicável à infraestrutura de rede em empresas de TI no Brasil.
Verificação prática: onde buscar informação oficial sem ruído
Comece com uma rotina de consulta a órgãos oficiais: ANATEL (autorização de serviço), Prefeitura do Rio (alvarás e ocupação de solo) e Receita Federal (inscrição fiscal). Para cada área técnica registre a informação coletada, data e contato. Essa prática transforma consultas isoladas em trilhas de auditoria úteis para provas de conformidade, principalmente quando houver fiscalização federal, estadual ou municipal no Brasil.
Implemente checklists padronizados por tema (licença, responsabilidade técnica, LGPD, segurança física). Exemplo prático: solicite à ANATEL documento de homologação do equipamento, confirme exigências de projeto estruturado junto à prefeitura e archive cada informacao em repositório com hashes e controle de versões. Essas etapas tornam a consulta repetível e permitem resposta imediata a auditorias ou solicitações judiciais no Brasil.
Aplique um fluxo de aprovação interno: técnico coleta informacao, jurídico valida obrigações e compliance assina termo de responsabilização. Em campo, use formulários digitais para registros de visita, fotos georreferenciadas e anexos de documentos; isso agiliza consulta posterior e reduz debates sobre fatos. Para contratos, anexe cláusulas específicas sobre responsabilidades regulatórias e revise trimestralmente com foco em mudanças normativas no Brasil.
Mapear órgãos relevantes (ANATEL, Prefeitura, Corpo de Bombeiros, ANPD) e contatos oficiais.
Documentar cada consulta: data, nome do atendente, protocolo e documento obtido.
Padronizar checklists técnicos e jurídicos para validação prévia de projetos.
Armazenar evidências em repositório seguro com controle de versões e backups.
Agendar revisões periódicas para atualizar obrigações legais e informar stakeholders.
Indicador relevante | Detalhe explicado |
Indicador relevante | Detalhe explicado |
Protocolo de consulta à ANATEL | Identifica data e validade da homologação de equipamento; sem protocolo há risco de embargo em obras de rede. |
Registro de LGPD e responsáveis | Define quem responde por dados pessoais coletados na infraestrutura; reduz passivo em caso de incidentes. |
Registrar cada consulta com evidência reduz litígios e acelera decisões operacionais críticas.
Estabeleça rotina onde consulta, documentação e revisão se cruzam: isso transforma obrigação legal em vantagem operacional mensurável.
11. Testes, certificações e técnicas de validação
Testes e certificações definem se a infraestrutura atende requisitos operacionais e regulatórios do Leblon; foco em técnicas de validação garante disponibilidade, segurança e conformidade com SLAs locais e normas setoriais.
Validação prática: do laboratório ao rack produtivo
Comece por validar tráfego e resiliência com testes de carga, latência e perda de pacotes em camadas física e lógica. Use técnica de validação de failover automatizada para verificar roteamento e HA; registre métricas (jitter, RTO, MTTR) em dashboards. Equipe técnico especializado deve executar testes em janelas controladas e comparar resultados com requisitos contratuais e planos de capacidade.
Certificações cabíveis para equipamentos e cabeamento (TIA/EIA, ISO/IEC) e para procedimentos (ISO 27001, PCI-DSS quando aplicável) servem como prova documental. Realize testes de certificação de cabeamento com certificador especializado, documente níveis de NEXT, ACR-F e ateste conformidade antes da entrega. Em ambientes Wi‑Fi, use sondas e heatmaps para validar cobertura e throughput com técnica de validação por site survey.
Integre testes automatizados no ciclo de deploy: scripts que executam smoke tests, verificação de ACLs, testes de autenticação RADIUS/LDAP e simulações de ataque de baixa intensidade para validar defesas. Registro de resultados e rotinas de reteste formam trilha de auditoria, essencial para clientes corporativos e órgãos reguladores. Contrate auditoria externa especializada anualmente para validação independente e atualização de controles.
Testes de performance: throughput, latência, jitter, perda de pacotes
Certificação física: testes de cabeamento e conformidade TIA/ISO
Validação operacional: failover, autenticação e testes de segurança
Indicador relevante | Detalhe explicado |
Indicador relevante | Detalhe explicado |
Tempo médio de recuperação (MTTR) | Medida prática do intervalo entre falha e restauração; determina SLAs e necessidade de automação de failover. |
Níveis de NEXT e ACR-F em certificação de cabos | Avalia interferência e margem de sinal; falha aqui impede certificação e funcionamento Gigabit/10G. |
Automatize testes regressivos e mantenha certificações atualizadas para reduzir MTTR e riscos contratuais.
Implemente plano de testes, registre evidências e renove certificações periodicamente para manter infraestrutura validada e auditável.
12. Integração entre filiais e colaboradores remotos: soluções práticas
Integração segura entre filiais e colaboradores remotos exige políticas, conectividade redundante e sistemas sincronizados para manter produtividade e conformidade em tempo real, reduzindo latência nos processos críticos do Leblon.
Conectar ativos locais e remotos sem comprometer desempenho
Detalhe prático: adote uma arquitetura híbrida com VPN site-a-site para filiais e acesso remoto por autenticação multifator para colaboradores. A integracao deve priorizar criptografia por túnel, segmentação de rede e rota de fallback. Implante monitoramento de desempenho com SLA interno (latência <30 ms entre sedes críticas) e logs centralizados para rastreamento de eventos e auditoria automática do sistema.
Exemplo aplicado: em um escritório no Leblon, configure um gateway SD-WAN para balancear tráfego entre fibra e backup 4G, garantindo continuidade na integraçao de aplicações de suporte ao cliente. Use interoperabilidade de protocolos para sincronizar sistema ERP local com instâncias em nuvem, replicando bancos de dados em horários de baixa carga para evitar impacto operacional.
Implementação imediata: padronize imagens de endpoint com agentes de gerenciamento que forcem atualizações, conexões seguras e criptografia em repouso. Estabeleça políticas de rota para priorizar VoIP e sistemas críticos, e crie playbooks para recuperação de integraçao após falhas. Treine equipes com simulação de falha em filial para validar runbooks e reduzir tempo médio de restauração do sistema.
VPN site-a-site + MFA para usuários remotos
SD-WAN com política de priorização de tráfego
Sincronização programada de banco de dados e backup offsite
Indicador relevante | Detalhe explicado |
Indicador relevante | Detalhe explicado |
Tempo médio de latência entre filiais | Latência abaixo de 30 ms mantém sistemas transacionais responsivos; acima de 80 ms exige otimização de rota ou link dedicado. |
Taxa de sucesso de autenticação remota | Meta acima de 99% indica integração de identidade funcionando; falhas recorrentes apontam necessidade de revisão do sistema de MFA ou sincronização de diretório. |
Priorize integraçao de identidade e segmentação de rede antes de ampliar largura de banda para reduzir riscos sem aumentar custos.
Implemente SD‑WAN, VPNs gerenciadas e sincronização de banco para garantir integraçao contínua entre filiais e colaboradores remotos, mantendo o sistema ágil e protegido.
13. Casos e experiências: sua experiencia de clientes e referências regionais
Relato objetivo de casos e referências regionais que comprovam impacto mensurável em disponibilidade e latência. Foco em sua experiencia com clientes locais, provas técnicas e marcos operacionais replicáveis.
Prova social técnica aplicada à infraestrutura de rede
Descrição precisa de projetos concluintes que servem como referência: destaque de sua experiencia em auditorias de rede, melhoria de SLA de 99,95% e redução de latência em 30% em ambientes corporativos. Em um projeto em Cuiabá foi validado tempo de convergência menor, transformando um contrato piloto em contrato anual, funcionando como marco regional que orientou ajustes em políticas de QoS.
Exemplos concretos: migração de backbone redundante para cliente financeiro com logs de queda reduzidos em 85% após reengenharia; implantação de segmentação por VLAN e firewall distribuído que replicamos em unidades de Cuiabá, com relatórios de performance usados como prova técnica. A visibilidade de sua experiencia está documentada em dashboards e nos certificados de teste que se tornaram marco para contratos subsequentes.
Aplicação direta para empresas do Leblon: use os mesmos scripts de validação, réplicas de topologia e planos de rollback testados em Cuiabá para acelerar entregas locais. Referências oficiais e contatos de clientes que validaram o projeto transformam cada marco numa checklist acionável; assim, sua experiencia passa a ser ferramenta de vendas e mitigação de risco operacional.
Relatório técnico com métricas pré/post implantação
Checklist de replicação do projeto aplicado em Cuiabá
Contato de referência que confirmou o marco de disponibilidade
Indicador relevante | Detalhe explicado |
Indicador relevante | Detalhe explicado |
Tempo médio de recuperação (MTTR) | Redução comprovada em projetos: descreve o impacto direto na continuidade e no SLA após ajustes de redundância |
Validação em ambiente regional (Cuiabá) | Testes em Cuiabá mostraram replicabilidade; use esses dados como referência operacional antes de expandir para o Leblon |
Documente cada marco com evidência técnica para transformar sua experiencia em argumento comercial verificável.
Forneça aos prospects relatórios, contatos e scripts de validação extraídos dos marcos; isso converte prova social em vantagem operacional imediata.
14. Planejamento de continuidade e evolução: do deploy à escala
Planejar continuidade significa alinhar deploys, automação e métricas para que a infraestrutura evolua sem interrupções. Este item foca táticas práticas para que a solução acompanhe crescimento da empresa e demandas do setor.
Transição controlada: do primeiro deploy à arquitetura preparada para picos
Característica central: definir uma pipeline de deploy versionada, testes automatizados e rollback claro. Implemente blue-green ou canary para liberar mudanças sem downtime, documentando cada release em runbooks. A solução precisa integrar CI/CD ao monitoramento para reduzir MTTR; a empresa obtém previsibilidade e o setor recebe SLAs consistentes. Registre métricas de sucesso por release para orientar priorização.
Funcionalidade exclusiva: escalonamento previsível por componentes. Separe camadas (core, serviços, borda) com limites de recursos e autoscaling configuráveis. Use simulações de carga trimestrais para validar thresholds e custos. Uma solução que combina infraestrutura como código e orquestração permite à empresa redistribuir capacidade automaticamente, prevenindo gargalos típicos do setor sem depender de intervenções manuais.
Aplicação prática: roteiro de 90 dias para evoluir após deploy inicial. Dia 0–30: observabilidade, alarmes e backups; 30–60: políticas de scaling e testes de recuperação; 60–90: otimização de custos e rolling upgrades. Ferramentas de gestão de configuração e políticas de segurança mantêm conformidade enquanto a solução expande. A empresa assim mantém desempenho previsível e atende requisitos regulatórios do setor.
Pipeline CI/CD com canary releases e rollback automatizado
Estrutura de camadas com limites de autoscaling e testes de carga periódicos
Runbooks, SLAs medidos e roteiro de 90 dias para evolução pós-deploy
Indicador relevante | Detalhe explicado |
Indicador relevante | Detalhe explicado |
Tempo médio de recuperação (MTTR) | Mostra a eficácia de rollback e runbooks; redução direta no impacto ao cliente e na reputação da empresa. |
Taxa de sucesso de deploys em produção | Percentual de releases sem rollback; indica maturidade da solução e maturidade operacional do setor. |
Priorize pipelines repetíveis: 70% das falhas de deploy podem ser evitadas com testes automatizados e rollback bem definidos.
Implemente o roteiro técnico e métricas desde o primeiro deploy; isso garante que a solução escale com segurança, protegendo a empresa no dinamismo do setor.
Conclusão
Uma infraestrutura de rede robusta transforma operações, reduz riscos e melhora competitividade local. Para uma Empresa de TI no Leblon, investir em arquitetura resiliente, monitoramento contínuo e planos de contingência traduz-se em serviço confiável e vantagem operacional mensurável.
Do investimento à vantagem competitiva local
Infraestrutura sólida não é custo isolado; é alavanca de produtividade e retenção de clientes. No Leblon, onde clientes corporativos e residenciais exigem latência baixa e disponibilidade contínua, prioridades incluem segmentação VLAN, redundância de enlace e políticas de QoS. Essas medidas diminuem chamadas de suporte, aceleram deploys e protegem SLAs, convertendo uptime em receita previsível e credibilidade técnica para a Empresa de TI no Leblon.
Implementação prática exige métricas acionáveis: tempo médio de recuperação, taxa de pacotes perdidos e variação de latência por horário. Ferramentas de monitoramento em tempo real e playbooks de resposta permitem isolar falhas antes de afetarem clientes-chave. Exemplos concretos incluem roteamento ativo-ativo entre dois ISPs locais e automação de patching em horários de menor tráfego, reduzindo janelas de manutenção e impactos comerciais perceptíveis.
Próximos passos claros: auditar topologia atual, priorizar correções por impacto no cliente e formalizar contratos de redundância com provedores regionais. Treinamento da equipe em troubleshooting de camada 2/3 e exercícios de failover minimizam erros operacionais. Para uma Empresa de TI no Leblon, essas ações resultam em diferenciação de mercado, menor churn e capacidade de ofertar SLAs mais agressivos com segurança operacional comprovada.
Auditoria de topologia e inventário de ativos críticos
Implementação de redundância de enlace e segmentação de rede
Monitoramento ativo com playbooks de resposta e testes de failover
Indicador relevante | Detalhe explicado |
Indicador relevante | Detalhe explicado |
Tempo médio de recuperação (MTTR) | Medida do tempo para restaurar serviços; reduz MTTR com playbooks e redundância diminui impacto no cliente. |
Taxa de perda de pacotes | Afeta desempenho de aplicações em tempo real; monitoramento contínuo identifica enlaces degradados ou congestão. |
Priorize automação e testes de failover: menos interrupções e mais confiança comercial para contratos locais.
Aplique auditoria, redundância e monitoramento agora; transforme infraestrutura em diferencial comercial e operacional para sua Empresa de TI no Leblon.
Perguntas Frequentes
O que uma empresa de TI no Leblon deve considerar ao planejar a infraestrutura de rede?
Ao planejar infraestrutura de rede, uma empresa de TI no Leblon precisa avaliar capacidade de banda, redundância, segurança e escalabilidade. Comece mapeando demandas de usuários, aplicações críticas e horários de pico para dimensionar links de internet, switches e roteadores adequadamente.
Também é essencial considerar cablagem organizada, pontos de acesso Wi‑Fi empresariais e soluções de backup de conectividade com fornecedores locais para garantir disponibilidade. Integrar políticas de segurança de rede e monitoramento proativo reduz riscos e facilita a gestão contínua.
Como garantir segurança de rede sem comprometer a performance?
Garanta segurança de rede adotando uma abordagem em camadas: firewall de próxima geração, segmentação de rede, autenticação multifator e criptografia de tráfego. Essas medidas protegem aplicações e dados sem necessariamente degradar a velocidade quando dimensionadas corretamente.
Monitore o desempenho com ferramentas de gerenciamento e ajuste políticas de qualidade de serviço (QoS) para priorizar tráfego crítico. Uma empresa de TI deve equilibrar políticas de segurança com otimizações de rede para manter baixa latência e alta disponibilidade.
Quais serviços uma empresa de TI no Leblon pode oferecer para manter a infraestrutura de rede?
Uma empresa de TI no Leblon pode oferecer consultoria em arquitetura de rede, instalação de cabeamento estruturado, configuração de switches e roteadores, implementação de Wi‑Fi empresarial e políticas de segurança. Serviços gerenciados incluem monitoramento 24/7, atualizações, backups e resposta a incidentes.
Além disso, suporte técnico presencial e remoto, testes de penetração e auditorias de conformidade ajudam a manter a infraestrutura confiável. Contratar um provedor de serviços gerenciados reduz a carga interna de TI e garante SLAs claros para disponibilidade.
Qual a importância da redundância e do backup de conectividade para empresas no Leblon?
Redundância e backup de conectividade são fundamentais para minimizar tempo de inatividade causado por falhas no link principal ou em equipamentos. Em um bairro como o Leblon, onde clientes e operações dependem de internet estável, ter links secundários ou LTE/5G como fallback garante continuidade.
Planos com balanceamento de carga e failover automático mantêm serviços críticos funcionando e protegem receitas e reputação. Combine redundância física (equipamentos duplicados) com redundância de link e processos de recuperação testados.
Como avaliar custo versus benefício ao contratar uma empresa de TI local no Leblon?
Avalie propostas considerando não apenas o preço, mas SLA, experiência com projetos semelhantes, tempo de resposta e cobertura de suporte. Verifique referências, certificações e se a empresa oferece serviços complementares como segurança de rede, monitoramento e manutenção preventiva.
Considere custos totais no ciclo de vida: investimento inicial em equipamentos, custos recorrentes de serviços gerenciados e economia obtida com redução de downtime. Um fornecedor local pode agregar valor com atendimento rápido e conhecimento do mercado carioca.
Que práticas de manutenção preventiva são recomendadas para manter uma infraestrutura sólida?
Implemente monitoramento contínuo de desempenho, atualizações regulares de firmware, revisão periódica da topologia e testes de backups. Inspecione cablagem e pontos de acesso, e faça auditorias de segurança para identificar vulnerabilidades antes que se tornem incidentes.
Agende manutenções fora do horário de pico, mantenha documentação atualizada e planos de contingência. Essas práticas, combinadas com suporte técnico proativo, prolongam a vida útil dos ativos e reduzem interrupções na operação.