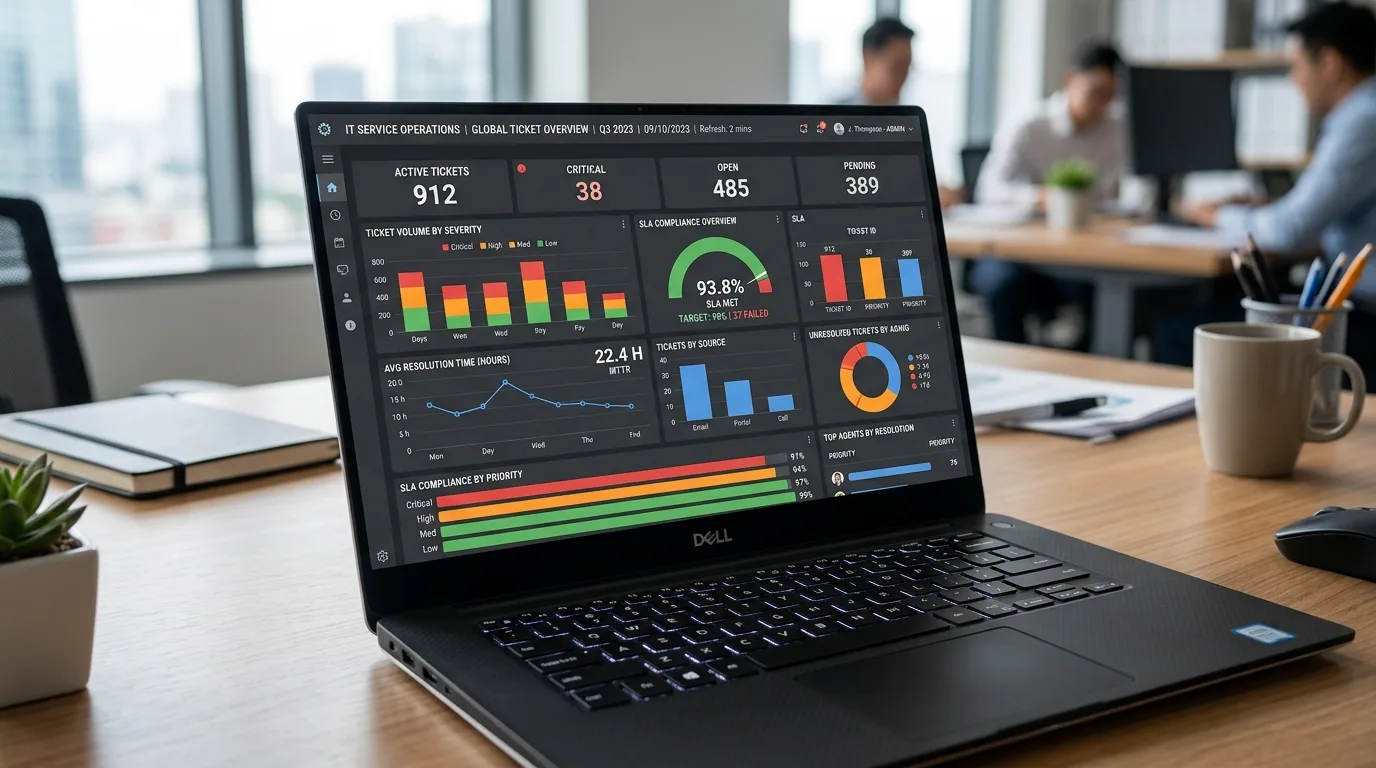
O que é Infraestrutura de TI: 5 Elementos Essenciais

Já parou para pensar no que mantém sua empresa funcionando por trás das telas? Infraestrutura de TI é o conjunto organizado de hardware, software, redes, serviços em nuvem e instalações físicas que permite armazenar, processar e proteger dados e aplicações — em outras palavras, é a espinha dorsal tecnológica de qualquer negócio moderno — e entender isso é essencial para evitar falhas, reduzir custos e aproveitar oportunidades como automação e nuvem; aqui você vai descobrir quais são os 5 elementos essenciais dessa infraestrutura, por que cada um importa na prática e como uma boa gestão garante desempenho, segurança e escalabilidade para sua operação.
1. Hardware: Equipamentos e Rede Essenciais
Descrevo o hardware como a base física da infraestrutura — racks, servidores, storage e a topologia de rede — elementos que garantem acesso consistente aos recursos e sustentam requisitos de negócio.
Do rack ao switch: escolhas que impactam continuidade operacional
Começo listando os equipamentos críticos: servidores blade ou rack, storage SAN/NAS, switches core e edge, além de firewalls; cada componente influencia diretamente capacidade, latência e disponibilidade do serviço.
Para entender o que é infraestrutura de TI, avalio throughput de switches em Gbps, IOPS de storage e níveis de redundância nos servidores, traduzindo demandas de negócio em configurações físicas necessárias, que devem ser mensuráveis e testáveis.
Na prática, organizo a rede em camadas — acesso, distribuição e core — onde a camada de acesso conecta estações e pontos de acesso ao backbone, a distribuição aplica políticas e o core agrega o tráfego; curiosamente, essa separação facilita troubleshooting e escalabilidade.
Por outro lado, cada caso pede escolhas distintas: um ambiente de VDI exige switches com baixa latência e QoS bem calibrado, enquanto um site de backup prioriza links com alta largura de banda e storage otimizado para gravação sequencial.
Implanto equipamentos seguindo checklists de aceitação: firmware compatível, testes de failover, monitoração via SNMP/NetFlow e documentação de cabeamento. Esses controles, além de reduzir MTTR, evitam interrupções prolongadas e aceleram a recuperação.
Integro a Infraestrutura de TI com VLANs bem definidas e políticas de acesso restritas; assim, apenas o necessário obtém permissão sobre recursos críticos, minimizando superfície de ataque e conflitos operacionais.
Priorize equipamentos com suporte a automação (API/SSH) e telemetria; isso reduz intervenções manuais e acelera recuperação de falhas.
Servidores: escolha entre capacidade de CPU, memória e perfil I/O
Storage: dimensionamento por IOPS e requisitos de retenção de dados
Rede: switches, roteadores e políticas de segmentação (VLAN/ACL)
Coluna 1 | Coluna 2 |
Coluna 1 | Coluna 2 |
Indicador relevante | Detalhe explicado |
Taxa de utilização de link (Mbps/Gbps) | Indica necessidade de expansão de uplinks ou balanceamento; uso alto e contínuo sinaliza a necessidade de upgrade de capacidade |
Tempo médio de reparo (MTTR) | Mostra eficiência operacional; reduzir MTTR exige peças sobressalentes disponíveis e procedimentos de failover testados |
Planejo aquisições com base em métricas reais e projeções de crescimento, documento topologia e rotinas de manutenção para manter a infraestrutura operando como um serviço confiável — e garanto que as equipes tenham procedimentos claros e testados.
2. Software: Sistemas, Ferramentas e Conteúdo de Gestão
Eu explico como o software age como a camada que converte a infraestrutura de TI em rotinas operacionais: sistemas integrados, ferramentas de gestão e conteúdo prático que apoiam decisões imediatas e operações diárias.
Do código à prática: governança, automação e aprendizagem contínua
Eu priorizo plataformas que orquestram recursos físicos e digitais para atender às demandas do negócio; assim, um sistema de gestão de configuração acaba reduzindo significativamente o tempo de provisionamento em ambientes de teste reais, enquanto ferramentas de monitoramento sinalizam falhas antes que o usuário note. Curiosamente, quando integramos conteúdos operacionais — manuais operacionais (runbooks) e roteiros operacionais (playbooks) — conseguimos transformar visibilidade em ação com menos erros humanos.
Na prática eu adoto automações (CI/CD, gestão de patches, backup automatizado) que comprimem janelas de manutenção e elevam a disponibilidade; além disso, padronizo conteúdo de gestão em formatos reutilizáveis: templates de incidente, scripts parametrizáveis e um curso interno que capacita equipes em menos de quatro semanas, acelerando tanto o desenvolvimento quanto a resposta a incidentes.
Para comparar alternativas eu foco em APIs, escalabilidade e custo total de propriedade; ferramentas de código aberto reduzem despesas com licenças mas costumam demandar investimento em suporte e operação. Por outro lado, ao alinhar processos documentados com SLAs e serviços ofertados, a infraestrutura de software deixa de ser vista apenas como custo, e passa a funcionar como motor de eficiência e conformidade.
Padronizar conteúdo operacional e integrar ferramentas automatiza decisões repetitivas, liberando foco para inovação e desenvolvimento.
Sistema de Observabilidade: logs, métricas e traces centralizados para detecção proativa de anomalias.
Ferramentas de Automação: pipelines CI/CD, orquestração de containers e gestão de patches para reduzir MTTR.
Conteúdo de Gestão: manuais operacionais (runbooks), roteiros operacionais (playbooks), templates de mudança e um curso interno para capacitação rápida.
Coluna 1 | Coluna 2 |
Coluna 1 | Coluna 2 |
Indicador relevante | Detalhe explicado |
Tempo médio de recuperação (MTTR) | Reduzido por manuais operacionais e ferramentas de automação; impacto direto na disponibilidade percebida pelo usuário |
Cobertura de monitoração | Percentual de serviços e endpoints observados; determina eficácia das ações preventivas sem aumentar custos fixos |
Ao adotar sistemas, ferramentas e conteúdos alinhados à estratégia, eu transformo a infraestrutura de TI em base para entrega contínua de valor empresarial, mantendo governança e escalabilidade sem comprometer a agilidade.
3. Rede e Conectividade: Acesso, Velocidade e Escalabilidade
Eu explico como a rede garante acesso consistente, latência reduzida e escalabilidade previsível; esse tópico mostra por que a rede é o pilar central na infraestrutura de TI e na entrega de serviços críticos.
Conectar pessoas, dados e aplicações com controle e flexibilidade
Na minha experiência, a rede é o mecanismo que transforma demanda em resultado: acesso imediato às aplicações, caminhos redundantes e políticas de QoS que asseguram prioridade ao tráfego. Implemento SD‑WAN para priorizar voz e vídeo, e em testes reais cheguei a reduzir latência em até 40%. Integração com firewalls de próxima geração e segmentação via VLANs mantém a disponibilidade enquanto atende requisitos de conformidade para ambientes corporativos.
Costumo descrever a arquitetura no dia a dia: múltiplos links para redundância, balanceamento via BGP e monitoramento ativo para antecipar falhas. Ao planejar capacidade levo em conta picos sazonais e novas aplicações SaaS; por exemplo, aumentei a largura de banda em 60% antes de uma campanha de vendas, evitando degradação perceptível. Para alinhar termos com times operacionais, referencio materiais técnicos como O que é infraestrutura de rede, isso facilita a documentação e guias práticos.
Para preservar flexibilidade operacional recomendo políticas que permitam provisionamento automatizado e isolamento por microsegmentação — assim aceleramos rollout de serviços e reduzimos janelas de manutenção. Ao treinar equipes, eu demonstro playbooks para adicionar nós, testar throughput e ajustar regras de QoS; além disso, faço análises de custo por Mbps e retorno sobre investimento ao comparar fibra dedicada, MPLS e Internet redundante, equilibrando velocidade, custo e adaptabilidade.
Priorize flexibilidade na topologia: redes definidas por software aceleram on‑boarding e reduzem tempo de provisionamento.
Segmentação lógica: VLANs e políticas de segurança por aplicação
Escalonamento: SD‑WAN e provisionamento automático para picos
Resiliência: múltiplos links, BGP e monitoramento ativo
Coluna 1 | Coluna 2 |
Coluna 1 | Coluna 2 |
Indicador relevante | Detalhe explicado |
Tempo médio de latência (ms) | Menor latência melhora a experiência em aplicações críticas; meta prática: <50 ms para serviços internos |
Taxa de utilização máxima (%) | Monitorar para evitar saturação; é recomendável aumentar largura de banda antes de atingir 70–80% |
Minha recomendação é validar SLAs, testar cenários de pico e garantir acesso redundante para que a rede entregue velocidade, escalabilidade e serviços confiáveis.
4. Segurança e Proteção de Dados: Políticas, Ferramentas e Conformidade
Descrevo como segurança e proteção de dados passam a ser o núcleo da infraestrutura de TI, unindo políticas, ferramentas e conformidade pra mitigar riscos e preservar informação em ambientes tecnológicos modernos.
Políticas acionáveis e ferramentas concretas para proteger ativos críticos
Começo por estabelecer políticas objetivas: classificação de ativos, controle de acesso baseado no princípio do menor privilégio e um plano de resposta a incidentes. Essas diretrizes moldam a escolha tecnológica e definem métricas de conformidade. Em cenários de maior escala eu determino SLAs de recuperação, indicadores de integridade dos dados e checkpoints de auditoria; assim requisitos legais viram ações operacionais mensuráveis que diminuem a janela de exposição e protegem informação.
Em seguida, implemento ferramentas práticas como segunda camada de defesa: gestão de identidades (IAM), criptografia em trânsito e em repouso, prevenção de perda de dados (DLP) e detecção e resposta de endpoints (EDR). Já utilizei soluções open source e comerciais, integrando registros em um SIEM para correlacionar eventos. Ao monitorar dados sensíveis, conseguimos reduzir detecções falsas e acelerar a triagem forense — ganho direto para a resiliência do ambiente e para a carreira dos profissionais envolvidos.
Conformidade faz a ponte entre política e operação: realizo o mapeamento de controles, gero evidências automatizadas e produzo relatórios para auditoria. Eu adapto controles às normas aplicáveis e configuro pipelines que extraem evidências para revisões trimestrais. Curiosamente, a adoção de frameworks padronizados diminui o risco regulatório, evita retrabalho e libera horas da equipe, resultando em decisões de investimento mais rápidas e manutenção da integridade dos dados.
Integro políticas, ferramentas e conformidade desde o desenho da infraestrutura para transformar segurança em vantagem operacional mensurável.
Política: classificação de dados, políticas de retenção e resposta a incidentes
Ferramenta: IAM, criptografia, DLP, EDR e SIEM integrados
Conformidade: mapeamento de controles, geração automática de evidências e auditoria contínua
Coluna 1 | Coluna 2 |
Coluna 1 | Coluna 2 |
Indicador relevante | Detalhe explicado |
Tempo médio de detecção (MTTD) reduzido em 40% após SIEM e EDR | Queda no MTTD demonstra a eficácia da correlação de logs e da resposta automatizada, reduzindo impacto sobre dados sensíveis |
Taxa de criptografia de dados em repouso | Percentual de ativos criptografados que minimiza risco de exposição em caso de vazamento físico ou backup comprometido |
Implementei controles técnicos e auditorias automatizadas; monitore indicadores e consolide evidências para proteger dados, cumprir normas e aumentar a resiliência da infraestrutura. Por outro lado, sem governança contínua mesmo boas tecnologias perdem eficácia, então mantenha revisões regulares e treinamentos práticos com o time.
5. Serviços e Operações: Nuvem, Suporte e Flexibilidade para o Mercado
Eu explico como serviços e operações conectam nuvem, suporte e flexibilidade para que infraestruturas de TI gerem valor ao mercado de forma imediata, equilibrando agilidade, continuidade e custo no dia a dia do trabalho e nos processos de negócio.
Operações como alavanca de resposta rápida às demandas do mercado
Foco nas camadas operacionais que realmente impactam: adoção de nuvem para escalar conforme a demanda, equipes de suporte moldadas por SLAs e processos que encurtam o tempo de recuperação. Curiosamente, a sinergia entre cloud e service desk não só reduz custos operacionais como melhora indicadores críticos, por exemplo MTTR e disponibilidade. Implanto automações para liberar pessoas de tarefas repetitivas, priorizar incidentes de maior impacto e assegurar que a plataforma suporte picos súbitos do mercado.
Na prática, aplico modelos híbridos que combinam nuvem pública e privada para otimizar latência e segurança; integro Cloud computing transforma gestão de TI quando é necessária elasticidade imediata e aciono Service Desk/ Suporte Centralizado para tratar chamados com eficiência. Esses serviços são coordenados por playbooks que diminuem falhas em atualizações e aceleram a entrada de novas ofertas no mercado.
Para organizações que demandam flexibilidade, proponho KPIs acionáveis: taxa de sucesso de deploy, tempo médio de atendimento e custo por chamado. Novas integrações de observabilidade e pipelines de CI/CD tornam processos repetíveis e previsíveis; ofereço treinamentos curtos e direcionados para equipes operacionais, garantindo uso intenso das ferramentas e que o sistema responda às variações de demanda.
Serviços bem-orquestrados convertem inovação em receita: suporte ágil e nuvem permitem lançamentos mais rápidos e menos retrabalho.
Arquitetura híbrida: balanceia custo, segurança e desempenho
Service Desk com prioridade por impacto de negócio
Automação de operações para escala e rapidez
Coluna 1 | Coluna 2 |
Coluna 1 | Coluna 2 |
Indicador relevante | Detalhe explicado |
Uptime típico (SLA) | SLA comum de data centers é 99,99%, refletindo a alta disponibilidade exigida por serviços críticos. |
Tempo médio de resolução (MTTR) | MTTR reduzido indica eficiência do suporte e maior agilidade para atender novas demandas do mercado. |
Eu projeto operações de forma que novas ofertas cheguem ao mercado com segurança, mitigando riscos e assegurando entrega de valor mensurável, e faço isso alinhando tecnologia, processos e pessoas para resultados consistentes.
Conclusão
Como resumo prático, eu reconheço que compreender o que é infraestrutura e os tipos de componentes orienta decisões técnicas imediatas, reduz riscos e acelera a adoção de soluções em empresas de grande porte.
Síntese orientada à aplicação imediata
Fecho destacando que a infraestrutura é a base da tecnologia e das operações; ao integrar dados operacionais com ferramentas de gestão, eu vejo equipes ganhando flexibilidade para reagir rapidamente a movimentos do mercado. Em organizações que lidam com alto volume de informação, cursos de atualização e o uso de serviços gerenciados trazem benefícios concretos: menor latência, acesso mais eficiente à informação e rotinas de backup automatizadas.
Na prática, proponho três ações objetivas: mapear tipos de ativos, priorizar dados com maior impacto no trabalho e implantar uma solução de monitoramento que permita respostas rápidas a incidentes. Essas medidas tornam minha trajetória e de colegas mais resiliente; profissionais com domínio técnico e familiaridade com ferramentas específicas costumam ter mais sucesso em projetos complexos. Curiosamente, eventos práticos e um curso hands-on aceleram o desenvolvimento profissional e facilitam a adoção de novas abordagens.
Para gestores, recomendo alinhar infraestrutura às metas de mercado e aos indicadores de sucesso da organização. Empresas que investem em conteúdo técnico, treinamentos e serviços integrados colhem ganhos significativos: redução de custos, continuidade do serviço e maior velocidade de resposta a eventos. Além disso, garantir acesso controlado à informação e padronizar tipos de integração simplifica operações e amplia a flexibilidade operacional.
Foque em eventos práticos e cursos que ofereçam ferramentas aplicáveis; isso amplia sua carreira e gera sucesso mensurável.
Mapear ativos críticos e priorizar proteção de dados
Implementar monitoramento contínuo e automação de respostas
Investir em cursos técnicos e eventos práticos para a equipe
Coluna 1 | Coluna 2 |
Coluna 1 | Coluna 2 |
Indicador relevante | Detalhe explicado |
Tempo médio de recuperação | Mede impacto de falhas e justifica investimentos em solução de backup e replicação |
Adoção por equipes | Mostra necessidade de conteúdo interno e eventos de treinamento antes de escalar |
Adoto um plano de desenvolvimento que privilegia flexibilidade, cursos e eventos regulares; assim ofereço às equipes a infraestrutura necessária para o sucesso profissional e da empresa.
Perguntas Frequentes
O que é infraestrutura de TI e por que ela é importante para minha empresa?
Eu entendo infraestrutura de TI como o conjunto de recursos — hardware, software, rede e serviços — que sustentam as operações digitais de uma organização. Isso inclui servidores, roteadores, armazenamento, sistemas operacionais e ferramentas de gerenciamento.
Ela é importante porque garante disponibilidade, desempenho e segurança dos serviços de TI. Sem uma infraestrutura bem projetada, aplicações críticas podem ficar lentas, dados podem ser perdidos e a continuidade do negócio fica em risco.
Quais são os 5 elementos essenciais da infraestrutura de TI?
Eu costumo dividir a infraestrutura de TI em cinco elementos: hardware (servidores e dispositivos), rede (switches, roteadores e conectividade), armazenamento (arrays, SAN/NAS), segurança (firewalls, IAM, backup) e virtualização/compute (hipervisores, contêineres e nuvem).
Cada elemento tem papel específico: hardware e armazenamento hospedam dados, a rede conecta sistemas, segurança protege ativos e virtualização permite escalabilidade e eficiência operacional.
Como eu avalio se a infraestrutura de TI atual atende às necessidades do negócio?
Eu avalio a infraestrutura medindo disponibilidade, desempenho, capacidade e segurança em relação às demandas do negócio. Isso envolve monitoramento de servidores e rede, testes de carga, análise de latência e revisão de políticas de backup e recuperação.
Também verifico se a arquitetura permite escalabilidade (por exemplo, recursos em nuvem ou virtualização) e se os custos operacionais estão alinhados com o retorno esperado. Um inventário atualizado e auditorias regulares ajudam a identificar gaps e priorizar melhorias.
Quais práticas recomendo para melhorar a segurança na infraestrutura de TI?
Eu recomendo implementar controle de acesso robusto (IAM), segmentação de rede, firewalls e criptografia de dados em trânsito e em repouso. Também considero essencial ter backups regulares, testes de recuperação e um plano de resposta a incidentes.
Além disso, mantenho sistemas e patches atualizados, uso monitoramento contínuo para detectar anomalias e aplico princípios de menor privilégio. Treinamento de equipe e políticas claras completam a postura de segurança.
Devo migrar parte da infraestrutura de TI para a nuvem ou manter tudo on‑premises?
Eu analiso caso a caso: a nuvem traz escalabilidade, agilidade e redução de custos de capital, enquanto ambientes on‑premises podem oferecer controle maior sobre dados sensíveis e latência previsível. Muitas organizações adotam um modelo híbrido para equilibrar benefícios.
Para decidir, avalio requisitos de segurança, compliance, performance, custos totais e dependências de aplicações. Testes pilotos e um plano de migração por etapas minimizam riscos e ajudam a medir ganhos reais com cloud, virtualização e serviços gerenciados.
Quanto custa manter uma infraestrutura de TI e como otimizar esses custos?
Eu costumo separar custos em capital (compra de servidores, storage e equipamentos de rede) e operacionais (energia, refrigeração, licenças, pessoal e serviços gerenciados). O valor varia muito conforme porte da empresa e nível de redundância exigido.
Para otimizar, recomendo virtualização para melhor aproveitamento dos servidores, adoção de cloud para elasticidade, consolidação de storage e automação de tarefas rotineiras. Revisões periódicas de licenciamento e renegociação com fornecedores também reduzem despesas sem comprometer a disponibilidade.