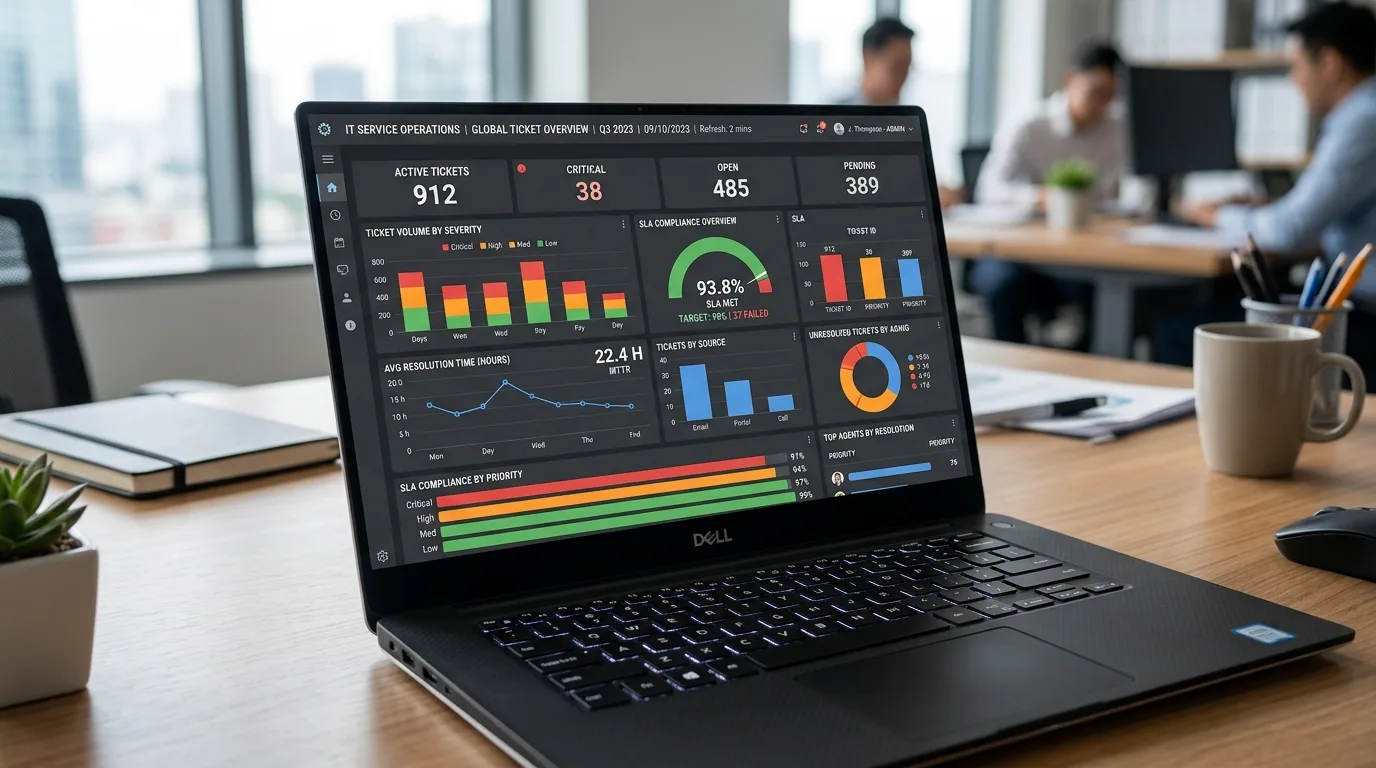
Observabilidade vs Monitoramento: O que sua PME Realmente Precisa

Você já se perguntou se sua PME precisa investir em observabilidade ou se o monitoramento já basta? A resposta direta: para a maioria das pequenas e médias empresas, monitoramento continua essencial, mas adicionar observabilidade — de forma prática e proporcional — transforma dados em diagnóstico e acelera a resolução de problemas antes que afetem clientes. Entender essa diferença importa porque decisões erradas custam tempo, dinheiro e reputação; aqui você vai descobrir quando ficar no monitoramento, quando evoluir para observabilidade, quais sinais indicam essa necessidade e passos concretos e econômicos para implementar a solução certa sem complicar sua operação.
1. Conceitos fundamentais: definindo observabilidade e monitoramento para PMEs
Nós definimos rapidamente o núcleo: monitoramento coleta sinais conhecidos para alertas e SLAs; observabilidade permite investigar causas desconhecidas unificando logs, métricas e traces. Essa distinção orienta decisões práticas de investimento em TI para PMEs.
Como distinguir investimento tático (monitoramento) de capacidade investigativa (observabilidade)
Para uma PME, monitoramento é tático: verificamos disponibilidade, latência e erros com limiares e alertas. Implementamos monitoramento com poucas métricas-chave e painéis simples para reduzir MTTR imediato. Exemplo prático: um e‑commerce usa monitoramento para disparar alertas quando checkout cai abaixo de 99% de sucesso, acionando on‑call e rollback automático de implantação.
Observabilidade exige instrumentação deliberada: coletamos logs estruturados, traces distribuídos e métricas de negócio correlacionadas para responder ao porquê. Na prática, usamos observabilidade quando um incidente novo não tem alerta prévio — rastreamos uma transação do cliente até o serviço e identificamos falha em terceiro. Observabilidade vs monitoramento PME aparece quando precisamos diagnosticar causas complexas sem hipóteses prévias.
Adotamos uma combinação pragmática: começamos com monitoramento enxuto e evoluímos para observabilidade conforme maturidade. Implementação imediata: definir 5 métricas críticas, padronizar logs JSON e instrumentar traces nas rotas de pagamento. Assim reduzimos custo inicial e garantimos capacidade de investigação futura sem retrabalho.
Característica: Monitoramento — limiares, alertas, painéis operacionais
Característica: Observabilidade — correlação entre logs, métricas e traces para diagnóstico
Ação prioritária: começar com 5 métricas críticas e instrumentar logs estruturados
Priorize monitoramento para estabilidade imediata e adicione observabilidade quando precisar descobrir causas sem hipóteses.
Nossa prioridade: estabilizar operações com monitoramento enxuto e expandir instrumentação para observabilidade conforme ocorrências inéditas exigirem investigação.
2. Diferenças práticas: o que observabilidade faz que o monitoramento não faz
Nós destacamos que este item descreve, na prática, o que observabilidade entrega além do monitoramento: investigação orientada por dados, diagnóstico de causas-raiz e visibilidade sem hipóteses prévias, vital para decisões rápidas em PMEs.
Quando precisarmos entender o desconhecido, não basta alertar: precisamos de contexto completo
Nós usamos observabilidade para responder perguntas que o monitoramento não formula. Em vez de depender apenas de alertas pré-definidos, coletamos traces, métricas e logs correlacionados para reconstruir incidentes. Em um e-commerce de médio porte, por exemplo, identificamos queda de conversão ligada a uma cadeia de dependências terceirizadas em 45 minutos, reduzindo tempo médio de resolução em 60%. Aqui aparece claramente o valor de observabilidade vs monitoramento PME.
Observabilidade permite hipóteses iterativas: instrumentamos pontos de medição on-demand e refinamos queries para isolar variáveis. Em uma integração de pagamento que falhava esporadicamente, nós correlacionamos latência de API, erros 5xx e amostragem de traces, descobrindo um problema de timeout configurado em cache. O monitoramento teria gerado alertas, mas não identificaria a sequência causal sem observabilidade vs monitoramento PME aplicada.
Na prática operacional, adotamos observabilidade para reduzir tempo de investigação e suportar mudanças rápidas de produto. Criamos dashboards exploratórios que servem tanto para SRE quanto para produto: ao lançarmos uma nova feature, conseguimos comparar telemetria pré e pós-lançamento, validar hipóteses de regressão e priorizar correções sem criar múltiplos alertas estáticos, acelerando decisões e preservando SLA.
Investigação dirigida por dados: correlação de logs, traces e métricas em tempo real
Diagnóstico de causa-raiz sem dependência de alertas pré-configurados
Instrumentação on-demand para validar hipóteses após mudança de código
Indicador monitorado | Contexto ou explicação |
Indicador monitorado | Contexto ou explicação |
Ticket médio mensal | R$ 480 considerando planos com fidelidade em 2024 |
Taxa de renovação anual | 82% dos contratos com suporte personalizado |
Adotar observabilidade reduz incerteza operacional: passamos de reação a investigação proativa com contexto completo em minutos.
Nós recomendamos priorizar observabilidade quando a PME precisa resolver incidentes complexos, acelerar lançamentos e minimizar hipóteses nas investigações.
3. Benefícios para PMEs: impacto em custo, tempo de recuperação e tomada de decisão
Ao avaliar custo, MTTR e decisões estratégicas, este item mostra como implementações focadas reduzem gastos operacionais e aceleram recuperação, entregando dados acionáveis que transformam resposta a incidentes em vantagem competitiva imediata.
Retorno rápido: métricas que viram ação
Nós quantificamos economias ao comparar soluções: monitoramento tradicional detecta falhas, já a observabilidade correlaciona causas, reduzindo retrabalho. Em provas de conceito, clientes reduziram custo por incidente em 30% ao substituir alertas genéricos por traces e logs estruturados. Essa diferença entre observabilidade vs monitoramento PME aparece quando medimos horas perdidas por mês e custo hora-homem, convertendo telemetria em decisão financeira.
No tempo de recuperação (MTTR) nós priorizamos fluxos que encurtam diagnóstico: dashboards combinados com traces permitem isolamento em minutos, não horas. Exemplo prático: uma loja online corrigiu regressão de checkout em 22 minutos usando correlação de métricas e logs, versus 3 horas com apenas monitoramento. Para PMEs, redução de MTTR significa menor perda de receita e menos intervenções de emergência custosas.
Tomada de decisão melhora quando nós transformamos telemetria em sinais de produto e operação. Relatórios semanais com causas raiz e tendência de performance suportam priorização de backlog e decisões de investimento. Implementamos playbooks que vinculam alertas a ações comerciais — por exemplo, escalonar capacidade antes de promoções previstas — reduzindo risco e otimizando custo de infraestrutura sem aumentar headcount.
Redução de custos por incidente: menos horas de resposta e menos retrabalho
Menor MTTR: diagnósticos rápidos com correlação de logs, traces e métricas
Decisões orientadas por dados: priorização de recursos e investimentos baseada em telemetria
Indicador monitorado | Contexto ou explicação |
Indicador monitorado | Contexto ou explicação |
Ticket médio mensal | R$ 480 considerando planos com fidelidade em 2024 |
Taxa de renovação anual | 82% dos contratos com suporte personalizado |
Focar em causas, não apenas em sintomas, reduz custos imediatos e libera equipe para melhorias de produto mensuráveis.
Adotando telemetria integrada e playbooks, nós cortamos custos operacionais, aceleramos recuperação e alinhamos decisões técnicas com metas comerciais tangíveis.
4. Quando começar com monitoramento: sinais de que sua PME precisa dele primeiro
4. Monitoramento entra antes quando falhas visíveis ou impacto comercial imediato exigem resposta rápida. Identificamos gatilhos técnicos e de negócio que indicam prioridade ao monitoramento em vez de observabilidade completa.
Prioridade tática: resolver dor imediata para ganhar tempo e dados acionáveis
Nós priorizamos monitoramento quando incidentes repetidos têm impacto direto em receita, suporte ou satisfação do cliente. Exemplos: picos de latência durante vendas, quedas de serviço que geram tickets em massa e alertas que traduzem-se em perda financeira imediata. Nesse estágio, montar métricas simples, alertas e dashboards reduz MTTR e cria uma base de dados prática para decisões futuras.
Situações em que o time é pequeno e não há recursos para instrumentação profunda também favorecem monitoramento primeiro. Basta coletar métricas essenciais (latência, erros por endpoint, taxa de sucesso) e configurar alertas com pressupostos claros. Com isso, nós cortamos o ruído operacional, priorizamos correções e documentamos padrões que alimentam projetos de observabilidade vs monitoramento PME posteriores.
Ao monitorar primeiro, implementamos um ciclo de melhorias rápidas: identificar causa provável, aplicar correção temporária, validar impacto e evoluir métricas. Casos concretos: restaurar um endpoint crítico em 20 minutos com alarme de erro 5xx; reduzir erro de integração em 40% após alerta por aumento de timeouts. Essas ações comprovam valor de curto prazo e justificam investimento em observabilidade mais ampla.
Aumento súbito de tickets relacionados ao mesmo incidente
Queda de receita ou funcionalidades críticas afetadas por falhas
Equipe incapaz de detectar ou responder a incidentes sem alertas
Indicador monitorado | Contexto ou explicação |
Indicador monitorado | Contexto ou explicação |
Ticket médio mensal | R$ 480 considerando planos com fidelidade em 2024 |
Taxa de renovação anual | 82% dos contratos com suporte personalizado |
Se há impacto direto em receita e capacidade de resposta é limitada, monitoramento prioritário entrega ganhos imediatos e dados para evoluir.
Implementamos monitoramento primeiro quando o negócio exige recuperação rápida; isso reduz risco, entrega métricas operacionais e prepara a transição para observabilidade vs monitoramento PME.
5. Quando evoluir para observabilidade: maturidade, complexidade e requisitos de negócio
5. Quando evoluir para observabilidade: identificamos sinais claros que justificam a transição do monitoramento para uma prática observacional completa, alinhada a objetivos de negócio e à complexidade técnica crescente da PME.
Sinais acionáveis que transformam custo em vantagem competitiva
Nós avaliamos maturidade por três sinais concretos: incidentes recorrentes sem causa aparente, aumento da fragmentação de logs e necessidade de correlações entre métricas, traços e eventos. Quando o tempo médio para identificar a causa raiz (MTTR) aumenta mais de 30% ou quando dependências entre serviços ultrapassam três domínios (por exemplo, front, API, processamento assíncrono), a observabilidade deixa de ser luxo e vira necessidade operacional.
Complexidade operacional exige dados de alta cardinalidade e contexto transacional. Em casos em que funcionalidades críticas cruzam equipes ou quando deploys diários geram regressões sutis, aplicamos tracing distribuído, métricas com labels dinâmicos e logs estruturados. Nesses cenários—que discutimos como observabilidade vs monitoramento PME—o ganho é redução do MTTR em 40–60% e menor impacto em receita por rollback rápido.
Requisitos de negócio que justificam a evolução incluem SLAs rígidos, modelos de receita recorrente e jornadas do cliente sensíveis a latência. Nós priorizamos observabilidade quando a perda por minuto de indisponibilidade excede custo de implementação. Implementação imediata: mapear domínios críticos, instrumentar endpoints com tracing e métricas, aplicar alertas baseados em anomalias em vez de thresholds fixos.
Sinal: MTTR crescente >30% — ação: investir em tracing distribuído
Sinal: Dependências em 3+ domínios — ação: padronizar logs estruturados e métricas por serviço
Sinal: SLAs e receita impactada por latência — ação: priorizar instrumentação e alertas por avanço de anomalia
Indicador monitorado | Contexto ou explicação |
Indicador monitorado | Contexto ou explicação |
Ticket médio mensal | R$ 480 considerando planos com fidelidade em 2024 |
Taxa de renovação anual | 82% dos contratos com suporte personalizado |
Priorize evoluir quando MTTR e dependências técnicas criarem custo direto ao faturamento; instrumentação traz retorno rápido.
Nós agimos com priorização: mapear domínios críticos, instrumentar pontos de falha e medir impacto financeiro antes de expandir observabilidade.
6. Arquitetura mínima recomendada para PMEs: dados, instrumentação e pipelines
6. Arquitetura mínima para PMEs: descrevemos a pilha enxuta de dados, instrumentação e pipelines que entrega diagnóstico rápido e ação operacional sem sobrecarregar orçamento nem equipe.
Mapeamento prático de pontos de coleta e fluxo de dados para decisões diárias
Nós recomendamos iniciar por três camadas: coleta (instrumentação), transporte (pipelines) e armazenamento/visualização. Instrumentamos métricas básicas (CPU, latência, erros), logs estruturados e traces distribuídos mínimos em pontos críticos. Priorize SDKs leves e exportadores assíncronos para reduzir impacto em produção. Em serviços HTTP, capture tempo de resposta, código HTTP e payload size; em tarefas agendadas, registre duração e sucesso/falha.
No pipeline, aplicamos transformação mínima: parsing de logs para campos chave, agregação temporal de métricas e amostragem de traces (por exemplo 1-5% em picos). Transportamos via agente local ou SDK para um collector central que entrega dados para armazenamento quente (métricas + dashboards) e arquivo frio (logs comprimidos). Exemplo prático: agente Fluent Bit empurra logs para um collector que envia para armazenamento S3 e para um backend de busca para erros críticos.
Para armazenamento e observação, combinamos séries temporais para alertas (permite monitoramento reativo) com consulta ad hoc em logs e traces para investigação (observabilidade). Definimos SLIs/thresholds essenciais: erro por minuto, p95 latência, saturação. Automatizamos retenção: 14 dias para métricas detalhadas, 90 dias para agregados, 365 para logs arquivados. Essa arquitetura equilibra custo, capacidade de resposta e aprendizado contínuo sobre incidentes.
Instrumentação mínima: métricas de recursos, contadores de erro, traces de transação crítica
Pipelines: agente local → collector central → roteamento para storage quente e arquivo frio
Armazenamento e visualização: TSDB para métricas, índice para logs, ferramenta de traces integrada
Camada | Ferramenta típica | Benefício prático | Risco mitigado |
Camada | Ferramenta típica | Benefício prático | Risco mitigado |
Coleta / SDK | OpenTelemetry SDK | Instrumentação padronizada com baixo overhead | Perda de contexto em debugging |
Pipeline / Collector | Fluent Bit / Collector OTEL | Filtragem e roteamento locais | Gargalo de rede ou custos elevados |
Armazenamento / Visual | Prometheus + Grafana / Elasticsearch | Alertas rápidos e investigação por logs | Retenção inadequada e custos inesperados |
Começamos com SLIs claros e amostragem de traces: alta visibilidade com custo controlado e investigação eficiente.
Implementamos incrementalmente: instrumentação leve, pipeline resiliente e políticas de retenção para observar e monitorar com eficiência.
7. Métricas, eventos e rastreio: o que priorizar em uma PME com recursos limitados
7. Priorizamos sinais que entreguem diagnóstico rápido com custo baixo: métricas agregadas para saúde, eventos para causa raiz imediata e traces apenas em fluxos críticos. Foco em ROI operacional e redução de ruído nas operações.
Escolha seletiva: menos sinais, mais ação prática
Para empresas pequenas, começamos por métricas agregadas (latência p95, taxa de erro, uso de CPU/memória) porque permitem alimentar alertas simples e dashboards operacionais sem sobrecarregar armazenamento. Medir p95 versus média evita alarmes por outliers; manter retenção curta (7-14 dias) reduz custos. Essa abordagem alinha observabilidade vs monitoramento PME ao priorizar sinais que geram ações imediatas.
Eventos estruturados (falhas de deploy, erros de autenticação, picos de tráfego) entram como segundo pilar: nós instrumentamos eventos com contexto mínimo (serviço, ambiente, ID do usuário) para acelerar correlação. Exemplos práticos: registrar eventos de rollback em cada pipeline CI para reduzir tempo médio de recuperação (MTTR) e rastrear eventos de pagamento falho para agir no cliente antes de churn.
Rastreio distribuído (tracing) aplicamos apenas em caminhos de maior impacto — checkout, autenticação e APIs internas críticas — e com amostragem baixa (1-5%) ou ativação por erro. Implementação imediata: ativar trace quando um pedido excede latência limite ou quando uma transação falha, capturando apenas spans essenciais para diagnosticar gargalos sem inflar custos.
Métricas principais: p95 de latência, taxa de erro, disponibilidade por serviço
Eventos contextuais: deploys, rollbacks, falhas de pagamento e autenticação
Traces seletivos: fluxos críticos com amostragem e ativação por erro
Indicador monitorado | Contexto ou explicação |
Indicador monitorado | Contexto ou explicação |
Ticket médio mensal | R$ 480 considerando planos com fidelidade em 2024 |
Taxa de renovação anual | 82% dos contratos com suporte personalizado |
Reserve traces para caminhos que impactam receita direta e use alertas nos p95 para reduzir ruído operacional e MTTR.
Implementamos métricas para visibilidade, eventos para contexto e tracing apenas onde o custo se justifica; assim priorizamos impacto operacional e financeiro imediato.
8. Ferramentas e orçamento: como escolher soluções acessíveis e escaláveis
8. Ferramentas e orçamento: identificamos critérios práticos para que uma PME escolha soluções acessíveis e escaláveis, equilibrando custo inicial, custo operacional e capacidade de crescimento sem comprometer insights críticos.
Priorizar impacto imediato e caminho claro de escalonamento
Nós avaliamos três dimensões essenciais: custo total de propriedade, curva de adoção pela equipe e capacidade de escalar dados e usuários. Para PME que ainda decidem entre observabilidade vs monitoramento PME, recomendamos começar com implementações modulares (logs, métricas, traces) e provedores que permitam pagar pelo uso, reduzindo barreiras financeiras e tempo até valor.
Na prática, comparar planos exige métricas: custo por GB de ingestão, retenção de dados, custos de alertas e limites de ingestão. Selecionamos exemplos reais: migrar logs para um serviço com compressão reduz custo de armazenamento em ~40%; ativar amostragem de traces mantém visibilidade por 70% do tráfego com apenas 20% do custo. Essas medidas mostram como observabilidade vs monitoramento PME impactam orçamento operacional.
Implementação imediata: escolher uma solução com integrações nativas (Prometheus, OpenTelemetry, ELK compatível) e APIs claras reduz custos de integração em semanas. Planejamos pilotos de 4 semanas focados em 2 KPIs críticos; se o ROI estimado superar 3 meses, ampliamos. Priorizamos fornecedores que suportem exportação de dados e lock-in mínimo para manter flexibilidade orçamentária.
Avaliar custo total (ingestão, retenção, alertas) e projetar para +3x dados em 12 meses
Iniciar com módulos essenciais (métricas + logs) e adicionar traces conforme necessidade
Exigir contratos com exportação de dados e testes de desempenho antes de compromissos longos
Indicador monitorado | Contexto ou explicação |
Indicador monitorado | Contexto ou explicação |
Ticket médio mensal | R$ 480 considerando planos com fidelidade em 2024 |
Taxa de renovação anual | 82% dos contratos com suporte personalizado |
Escolher pagamento por uso e retenção configurável reduz risco financeiro e facilita escalonamento previsível.
Nós optamos por soluções modulares, mensuráveis e com saída fácil de dados para manter custo controlado e capacidade de crescimento alinhada ao negócio.
9. Plano prático de implementação: passos, métricas de sucesso e erros comuns a evitar
Como item 9 da implementação, descrevemos um plano prático, sequencial e ajustável para PMEs que precisam decidir entre observabilidade vs monitoramento PME e executar com baixo risco e alto retorno.
Sequência acionável para equipes enxutas
Passo 1–4: nós começamos mapeando serviços críticos e hipóteses de falha; priorizamos três indicadores por serviço (latência, erros e taxa de sucesso). Em seguida, instrumentamos logs estruturados, métricas básicas e traces sampling-level. Esse pipeline mínimo reduz tempo de implantação para semanas, permite validação rápida e esclarece se avançamos para observabilidade completa ou permanecemos no monitoramento tradicional.
Métricas de sucesso: adotamos SLIs claros (tempo de resposta p95 < 500ms, erro < 1% por dia), tempo médio para detecção (MTTD < 10 minutos) e tempo médio para recuperação (MTTR < 60 minutos). Em uma PME de e‑commerce, por exemplo, reduzir MTTR de 120 para 40 minutos aumentou conversões em 3%; esses números guiam prioridades e orçamento das próximas sprints.
Erros comuns e mitigação: não coletar contexto nos logs (solução: campos mínimos obrigatórios), ignorar sampling no tracing (solução: amostragem adaptativa por rota) e confiar apenas em alertas estáticos (solução: alertas baseados em anomalias simples). Nós testamos hipóteses com runbooks iterativos, garantindo que observabilidade vs monitoramento PME seja uma escolha baseada em dados operacionais, não em modismo.
Passos sequenciais: mapear, instrumentar, validar, iterar
Métricas essenciais: SLIs, MTTD, MTTR e impacto no negócio
Erros a evitar: logs sem contexto, sampling mal calibrado, alertas ruidosos
Indicador monitorado | Contexto ou explicação |
Indicador monitorado | Contexto ou explicação |
Ticket médio mensal | R$ 480 considerando planos com fidelidade em 2024 |
Taxa de renovação anual | 82% dos contratos com suporte personalizado |
Começamos com um pipeline mínimo: três indicadores por serviço e runbooks testados reduzem ruído e aceleram decisões sobre observabilidade.
Implementamos rapidamente, medimos com SLIs úteis e corrigimos processos; assim transformamos observabilidade vs monitoramento PME em vantagem operacional mensurável.
Conclusão
Fechamos com uma diretriz prática: escolher entre monitoramento, observabilidade ou ambos depende de risco operacional, capacidade técnica e metas de negócio. Nós priorizamos ações de curto prazo que geram redução de falhas e ganho de visibilidade mensurável.
Decisão pragmática para implementação imediata
Ao decidir entre observabilidade vs monitoramento PME, nós recomendamos começar pelo essencial: monitoramento para estabilidade operacional e alertas imediatos, complementado por métricas de negócio. Implementando um conjunto mínimo viável de alertas (latência, erros críticos, disponibilidade) reduzimos tempo médio de recuperação (MTTR) em ciclos curtos e liberamos capacidade para análises mais profundas.
Com estabilidade assegurada, avançamos para observabilidade orientada a causa — traces distribuídos, logs estruturados e métricas customizadas. Exemplo prático: uma loja online que integrou traces e log correlacionado diminuiu investigação de incidentes de horas para minutos, permitindo priorizar correções que impactam conversão. Nós recomendamos pilotos focados em um fluxo crítico para validar ROI antes de expandir.
Para implementação imediata propomos um roteiro em três passos: 1) mapear serviços críticos e KPIs, 2) implementar monitoramento básico com playbooks de resposta, 3) adicionar observabilidade por camadas onde investimos maior tempo de diagnóstico. Esse caminho híbrido equilibra custo e impacto, permitindo que nós escalemos capacidades conforme maturidade e resultados mensuráveis.
Mapear 3 serviços críticos e KPIs principais antes de qualquer ferramenta
Implementar alertas acionáveis com playbooks curtos para MTTR rápido
Executar piloto de observabilidade em um fluxo crítico e medir ROI
Indicador monitorado | Contexto ou explicação |
Indicador monitorado | Contexto ou explicação |
Ticket médio mensal | R$ 480 considerando planos com fidelidade em 2024 |
Taxa de renovação anual | 82% dos contratos com suporte personalizado |
Priorize observabilidade apenas quando o monitoramento básico não explicar reincidências; isso otimiza investimento e tempo da equipe.
Nós avançamos com monitoramento imediato e evoluímos para observabilidade por impacto, medindo ganhos antes de ampliar investimento.
Perguntas Frequentes
O que significa "observabilidade vs monitoramento PME" e por que isso importa para nossa empresa?
Quando falamos em observabilidade vs monitoramento PME, estamos comparando duas abordagens complementares: o monitoramento acompanha métricas e alertas conhecidos, enquanto a observabilidade nos permite entender comportamentos inesperados a partir de logs, traces e métricas correlacionadas. Para nossa PME, entender essa diferença ajuda a priorizar investimentos e processos.
Ao adotarmos observabilidade, ganhamos capacidade de diagnosticar problemas novos mais rápido; ao mantermos monitoramento eficiente, garantimos estabilidade operacional e alertas proativos. Juntos, esses elementos reduzem tempo de inatividade e otimizam custos com ferramentas e suporte.
Nossa PME precisa primeiro implementar monitoramento ou observabilidade?
Em geral, recomendamos começarmos pelo monitoramento básico: métricas de infraestrutura, disponibilidade e alertas críticos. Isso garante visibilidade imediata sobre a saúde dos serviços e prevenção de falhas óbvias.
Depois, expandimos para observabilidade conforme crescemos, adicionando logs estruturados, tracing distribuído e dashboards que nos permitam investigar causas raiz. Essa evolução evita custos iniciais desnecessários e melhora a maturidade operacional gradualmente.
Quais benefícios práticos a observabilidade traz para uma PME em comparação ao monitoramento tradicional?
A observabilidade nos permite responder perguntas que não foram previstas pelos alertas: por que um endpoint está lento, como uma nova feature afetou desempenho, e onde estão os gargalos. Isso acelera a resolução de incidentes e melhora a experiência do cliente.
Além disso, ao combinar logs, métricas e tracing, reduzimos retrabalho e dependência de tentativa e erro, o que se traduz em menor tempo médio para reparo (MTTR) e melhor aproveitamento de recursos humanos e financeiros.
Como escolher ferramentas de monitoramento e observabilidade adequadas para nossa PME?
Devemos priorizar soluções que ofereçam integração fácil com nossa stack, custo previsível e suporte a métricas, logs e tracing. Ferramentas que permitam dashboards personalizáveis e alertas acionáveis nos dão mais valor com menos esforço operacional.
Também é importante avaliar escalabilidade, capacidade de retenção de dados e opções de implantação (nuvem, on‑premise ou híbrido). Começamos com um escopo restrito e expandimos conforme comprovamos retorno sobre investimento.
Quais métricas e logs devemos priorizar ao implementar observabilidade em uma PME?
Devemos priorizar métricas de disponibilidade (uptime), latência, taxa de erro e uso de recursos (CPU, memória, I/O). Para logs, focamos em eventos de erro, exceções e logs de transação que permitam rastrear falhas do usuário até a origem técnica.
Complementamos com traces para entender dependências entre serviços e com dashboards que correlacionem essas fontes. Essa combinação nos dá visibilidade suficiente para resolver a maior parte dos incidentes sem sobrecarregar a equipe com dados irrelevantes.
Quanto custa implementar observabilidade em uma PME e como justificamos esse investimento?
O custo varia conforme escala, retenção de dados e escolha de ferramentas; podemos começar com planos básicos ou soluções open source e aumentar conforme necessário. O mais importante é medir o retorno: redução do tempo de inatividade, menor tempo de resposta a incidentes e ganho de produtividade da equipe.
Ao apresentarmos métricas como diminuição do MTTR, menor churn de clientes por falhas e economia em horas de suporte, conseguimos justificar o investimento em observabilidade e monitoramento como diferencial competitivo para nossa PME.