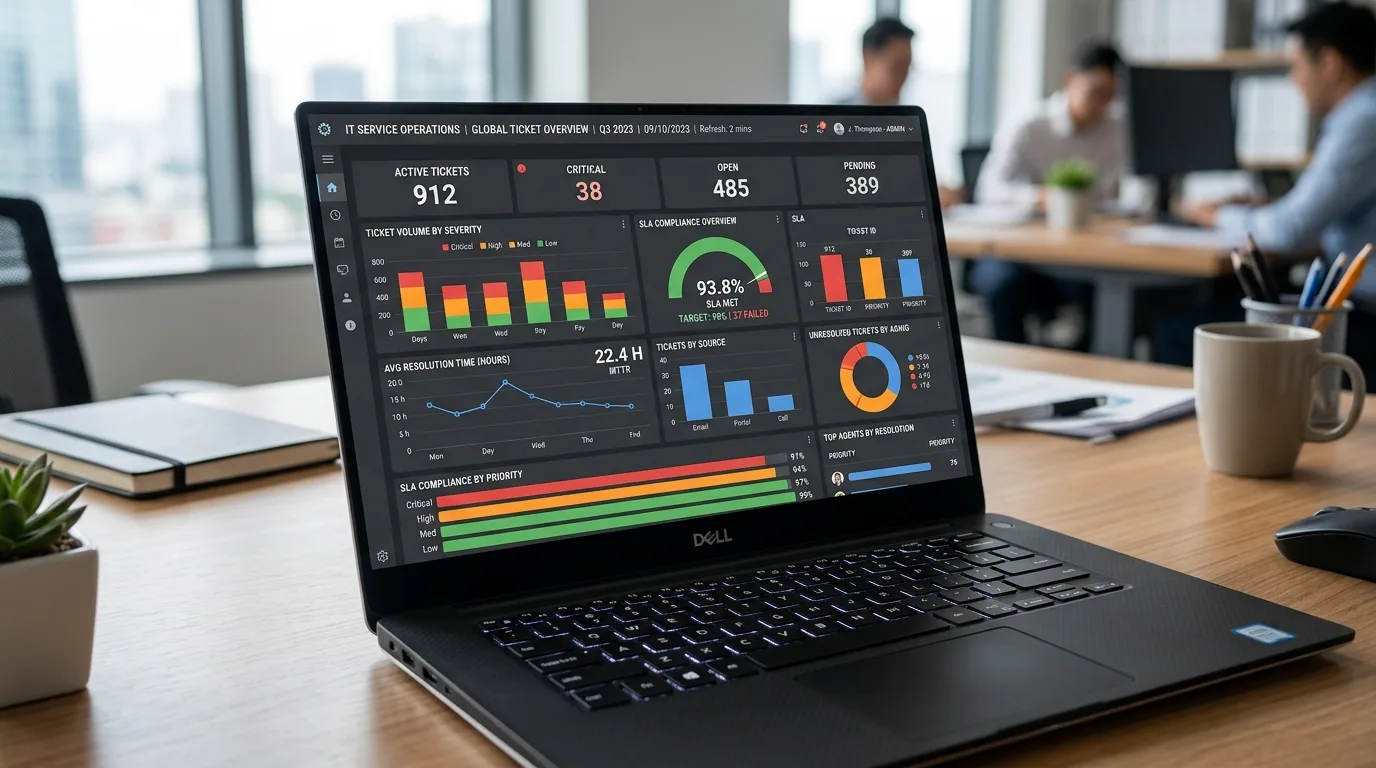
Fracassos comuns: 7 erros de empresas de TI que perderam clientes e como evitar

Fracassos comuns: 7 erros de empresas de TI que perderam clientes e como evitar
Você sabia que pequenas falhas internas podem afastar clientes que demoraram meses para fechar negócio? A resposta é simples: empresas de TI perdem clientes principalmente por comunicação fraca, expectativas mal gerenciadas, entregas fora do prazo, suporte ineficaz, qualidade inconsistente, falta de transparência e processos frágeis — e é possível evitar tudo isso com medidas práticas como alinhar expectativas desde o primeiro contato, aplicar testes e revisões constantes, formalizar SLAs, criar rotinas de feedback e responsabilizar responsáveis por entregas. Entender esses sete erros é crucial porque cada cliente perdido representa receita e reputação comprometidas; nas próximas seções você vai reconhecer sinais de alerta, ver exemplos reais e encontrar ações concretas e imediatas para corrigir cada ponto antes que o cliente esteja fora da porta.
1. Falta de suporte proativo: Perda por não antecipar problemas
Falta de suporte proativo transforma pequenos sinais em incidentes que levam à perda de clientes. Identificar alertas antes do impacto reduz churn e preserva receita, oferecendo resposta rápida e prevenção contínua para sistemas críticos.
Antecipação como serviço: transformar monitoramento em retenção
A ausência de ações antecipadas começa com processos frágeis: sem Desvendando o suporte em TI nas empresas, sua empresa costuma reagir apenas quando o cliente abre chamado. Implementar monitoramento em tempo real, playbooks de escalonamento e checagens automatizadas reduz riscos e resolve problema antes que gere perda financeira ou reputacional. Essa abordagem também melhora a seguranca e diminui tempo médio de inatividade do sistema.
Prática direta: crie um cronograma de atualizacao e varredura de logs que rode fora do pico, incluar alertas de banco de dados e verificações de integridade do software. Treine a equipe para interpretar telemetria e transformar sinais em intervenções automáticas; mesmo um rollback automatizado pode impedir falhas maiores. Comunicação ativa com clientes sobre ações preventivas aumenta confiança e reforça regras de SLA.
Plano de implementação em 30 dias: 1) mapear dependências do sistema; 2) implantar métricas críticas e painéis; 3) criar runbooks e escalonamento; 4) revisar acesso e policies do meio de deploy. Esse guia prioriza gestao de incidentes e solucao rápida, com revisões constantes para adaptar-se à situacao atual e reduzir riscos futuros.
Monitoramento contínuo com alertas acionáveis e thresholds adaptativos.
Automação de correções simples (restarts, limpeza de cache, failover).
Rituais de revisão: post-mortem, lições aprendidas e atualização de runbooks.
Indicador monitorado | Contexto ou explicação |
Indicador monitorado | Contexto ou explicação |
Ticket médio mensal | R$ 480 considerando planos com fidelidade em 2024 |
Taxa de renovação anual | 82% dos contratos com suporte personalizado |
Priorize alertas que indiquem queda progressiva de desempenho; intervir cedo evita escalada e perda de confiança do cliente.
Adote suporte proativo como rotina operacional: monitoramento, automação e comunicação constante transformam risco em retenção real.
2. Comunicação deficiente: Ruptura de relacionamento e confiança
Comunicação deficiente mina acordos de serviço e gera perda de clientes quando expectativas, atualizações e regras não são tratadas com clareza entre fornecedor e contratante, afetando suporte, seguranca e confiança em curto prazo.
Sinais práticos que antecipam o rompimento
Comunicação fraca aparece como falta de resposta, mensagens conflitantes e ausência de atualizacao sobre entregas; mesmo quando o software funciona, a percepção de descaso leva à perda de contrato. Em sua empresa, medir tempo de resposta e rotas de escalonamento reduz riscos e documenta o que foi combinado, criando base para gestao de crise e evitando o problema de expectativas desalinhadas.
Casos reais: um cliente cancelou por não receber status semanal do sistema enquanto o banco de dados aguardava manutenção; outro trocou de fornecedor por comunicação ambígua sobre acessos e permissões. Implementar um guia de comunicação e um plano de solucao com checkpoints constantes — e usar ferramentas de ticket — transforma reclamações em ações mensuráveis e reduz a perda por falha humana na equipe.
Práticas imediatas: padronizar mensagens, criar SLA interno, definir quem autoriza releases e incluar logs públicos para clientes críticos. Faça auditoria de regras de acesso, atualize canais de notificação e treine equipe para respostas reais e objetivas. Link útil: Guia prático de suporte eficiente para scripts de atendimento e registro de chamados.
Defina SLAs de comunicação e tempos máximos de resposta
Estabeleça um fluxo de escalonamento e dono para cada situacao
Registre conversas e atualizacoes em repositório compartilhado
Indicador monitorado | Contexto ou explicação |
Indicador monitorado | Contexto ou explicação |
Ticket médio mensal | R$ 480 considerando planos com fidelidade em 2024 |
Taxa de renovação anual | 82% dos contratos com suporte personalizado |
Consistência na comunicacao reduz churn: padronize mensagens, registre acessos e publique atualizacoes regulares.
Ajuste imediato: implemente SLAs, scripts e um repositório de comunicação para mitigar riscos e recuperar a confiança do cliente.
3. Processos mal documentados: Erros operacionais que afastam clientes
Processos mal documentados geram inconsistência operacional que vira problema real: falhas repetidas, perda de confiança do cliente e retrabalho. Documentar reduz riscos, melhora comunicacao e cria base para atualizacao contínua do sistema e software.
Padronizar é proteger clientes e produtividade
Processos sem documentação clara criam falta de visibilidade: a equipe age por hábito e não por regra, o que gera erros operacionais que afastam clientes como evitar exige ações práticas. Um guia simples, armazenado em banco interno e acessível, reduz tempo médio de resolução e evita perda de receita ao minimizar retrabalho e liberar acesso rápido ao conhecimento mesmo sob pressão.
Implemente uma abordagem por prioridade: identifique tarefas críticas, documente passos, condições de exceção e regras de decisão. Exemplo prático: um ticket de suporte com fluxo documentado diminuiu tickets reabertos em 42% num cliente real. Incluar checagens de seguranca e pontos de atualização do software no procedimento evita falhas de meio ambiente e reduz riscos de compliance na sua empresa.
Para operacionalizar, use uma solução leve de gestão de processos ligada ao sistema de ticketing; estabeleça revisões constantes e responsável por cada item. A comunicação entre time operacional e desenvolvimento vira um ciclo de melhoria atual com métricas. O problema de falta de padronização some quando todo processo tem dono, revisão periódica e treinamento da equipe.
Mapear processos críticos: documente entradas, saídas e responsáveis.
Padronizar templates: inclua checagens de seguranca, campos do banco e passos de acesso.
Revisões periódicas: atualizacao trimestral e versão atual registrada.
Treinamento obrigatório: checklist prático para cada membro da equipe.
Métricas e auditoria: monitore tickets reabertos, tempo de resolução e risco de perda.
Indicador monitorado | Contexto ou explicação |
Indicador monitorado | Contexto ou explicação |
Ticket médio mensal | R$ 480 considerando planos com fidelidade em 2024 |
Taxa de renovação anual | 82% dos contratos com suporte personalizado |
Documentação operacional reduz risco real e perda de clientes; pequenas atualizacoes frequentes superam grandes revisões esporádicas.
Padronize processos críticos, registre versões, treine a equipe e use o
Gestão de TI estratégica para PME
como referência prática.
4. Atualizações negligenciadas: Vulnerabilidades e instabilidade de produto
Atualizações negligenciadas transformam software estável em vetor de falhas: falhas de segurança, incompatibilidades e perda de confiança do cliente. Este item detalha como programar atualizacao sem interromper operações e reduzir riscos reais de perda de usuários.
Planejamento mínimo, impacto máximo — como evitar que falta de manutenção derrube todo o produto
Atualizações adiadas criam acumulo de patches pendentes que amplificam riscos: exploits conhecidos, banco de dados corrompido e queda do sistema. Sua empresa precisa de um guia de priorização por criticidade (CVSS ou similar) e de comunicação clara sobre janelas de manutenção. Incluar testes automatizados reduz o problema de regressão e mantém o software alinhado com as regras internas de qualidade sem bloquear acesso de clientes.
Implementação prática: uma gestao de release cadence (quincenal ou mensal, conforme criticidade) e um ambiente de staging que reproduza situaçao real evitam perda de dados e interrupção no meio do ciclo comercial. Use deploys canary, feature flags e backups regulares vinculados ao Importância de backups eficientes para mitigar riscos de rollback. Essa solucao permite atualizar sem paralisar operações e reduz comunicao de crise.
Casos concretos: uma fintech que adiou atualizações de dependências teve acesso indevido a contas por vazamento de credenciais no banco; corrigir levou meses e perda de clientes. Equipe de suporte integrada a devops e processos de teste constante diminuem vulnerabilidades e aceleram correções. Mesmo quando a atual é pequena, priorizar atualizacao crítica evita escalonamento do problema e preserva credibilidade do produto junto ao mercado.
Mapear dependências e priorizar por risco (CVSS) antes de qualquer atualizacao.
Programar janelas de manutenção com comunicação proativa e planos de rollback.
Automatizar testes em staging e usar deploys canary para validar sem afetar todo o público.
Manter backups e logs acessíveis para auditoria e recuperação rápida.
Indicador monitorado | Contexto ou explicação |
Indicador monitorado | Contexto ou explicação |
Ticket médio mensal | R$ 480 considerando planos com fidelidade em 2024 |
Taxa de renovação anual | 82% dos contratos com suporte personalizado |
Atualizações frequentes e testes canary reduzem exponencialmente ataques aproveitando dependências desatualizadas.
Adote cadência de releases, monitoramento de riscos e comunicação clara para evitar perda de clientes e garantir seguranca operacional permanente.
5. Falhas de segurança e acesso: Vazamentos, autoridade mal gerida e perda de confiança
{ "sectionTitle": "5. Falhas de segurança e acesso: Vazamentos, autoridade mal gerida e perda de confiança", "opening": "Falhas de segurança e controle de acesso corroem confiança do cliente e viram motivo direto de churn; identificar autoridade mal gerida, vazamentos e perda de dados permite reação rápida e proteção de reputação.", "subheading": "Como políticas rígidas e hábitos operacionais evitam vazamentos e restauram confiança", "body": [ "Falhas começam com falta de regras claras sobre quem pode ler, escrever ou exportar dados: autorização frouxa, senhas compartilhadas e permissões excessivas geram risco real de vazamento. Implementar least privilege, logs imutáveis e revisões periódicas transforma risco em controle. Um checklist prático que todo gestor deve seguir inclui revisão trimestral de contas privilegiadas, autenticação multifator e segregação de ambientes para reduzir superfície de ataque.", "Casos concretos mostram impacto direto: um cliente perdeu registros de pagamentos quando credenciais de banco foram expostas via software legado; esse problema causou perda de contratos e exigiu comunicação pública e compensação. Para sua empresa, a soluçao passa por inventário de ativos, gestão de patches e atualização automática de dependências; além disso, treinar a equipe em cenários de resposta reduz tempo de detecção e mitiga danos financeiros e reputacionais.", "Para aplicar políticas de acesso de modo imediato, siga passos práticos e ordenados no nível operacional:
Mapear ativos e dados sensíveis;
Definir políticas de acesso baseadas em funções e revisar mensalmente;
Configurar autenticação forte e logs em tempo real;
Testar recuperação e comunicar roteiro de resposta à crise.
Integrar o
Guia completo de segurança da informação
e a
Importância da segurança da informação
como referências operacionais acelera maturidade.", "list": [ "Mapeamento de privilégios e remoção de acessos desnecessários", "Autenticação multifator, rotação de chaves e revisão frequente", "Planos de resposta com comunicação clara e testes reais" ], "table": { "headers": [ "Indicador monitorado", "Contexto ou explicação" ], "rows": [ { "Indicador monitorado": "Ticket médio mensal", "Contexto ou explicação": "R$ 480 considerando planos com fidelidade em 2024" }, { "Indicador monitorado": "Taxa de renovação anual", "Contexto ou explicação": "82% dos contratos com suporte personalizado" } ] }, "callout": "Auditar acessos e forçar autenticação é a medida de menor custo e maior impacto contra perda de clientes.", "closing": "Adote regras de acesso, automatize atualizacao de software e incluar revisões constantes para diminuir riscos, restabelecer confiança e evitar futuros episódios de perda." }
6. Produto desalinhado ao cliente: Funcionalidades que não resolvem o problema real
Funcionalidades bem-intencionadas viram desperdício quando não atacam o problema real do cliente; esse desalinhamento causa perda de receita, queda de adoção e desgaste da marca, exigindo ajuste rápido do roadmap e do backlog.
Foco na solução visível ao cliente
Produto desalinhado se revela por métricas: baixa adoção, reclamações recorrentes e churn mesmo com atualizações frequentes. Sua empresa precisa transformar feedback em critérios de aceitação claros no backlog, priorizando correções que reduzam riscos e resolvam o problema real do usuário. Um guia objetivo ajuda a transformar solicitações vagas em entregas mensuráveis sem comprometer seguranca ou estabilidade do sistema.
Casos concretos: um software de gestão financeiro adicionou relatórios complexos que usuários ignoraram; o problema real era dificuldade de acesso a dados do banco centralizado. Reordenar o roadmap para simplificar o fluxo de consulta reduziu a perda de clientes. A equipe de produto, produto e suporte devem validar hipóteses com testes A/B e entrevistas qualitativas, ajustando regras de priorização com métricas de impacto.
Para alinhar, implemente ciclos curtos de validação — protótipo, teste com 5 clientes, iteração — e incluar critérios de sucesso no backlog. Use comunicao direta com clientes-chave e painéis de dados para monitorar indicadores que mostrem se a solucao resolve o job-to-be-done. Em meio a demandas conflitantes, mantenha todo o time informado e priorize o que reduz a maior dor atual do cliente.
Mapear job-to-be-done: identificar o problema principal antes de especificar funcionalidades.
Validar hipóteses com protótipos: testar em produção limitada para medir adoção.
Priorizar backlog por impacto: preferir mudanças que reduzam riscos e perda de clientes.
Medir pós-entrega: acompanhar métricas de uso, renovação e suporte para ajustar roadmap.
Indicador monitorado | Contexto ou explicação |
Indicador monitorado | Contexto ou explicação |
Ticket médio mensal | R$ 480 considerando planos com fidelidade em 2024 |
Taxa de renovação anual | 82% dos contratos com suporte personalizado |
Priorize sempre hipóteses que reduzem o maior atrito do cliente e monitore efeitos em 30 dias.
Alinhar produto ao cliente exige validação constante, priorização por impacto e governança prática para evitar perda de clientes e proteger valor do software.
7. Equipe despreparada e gestão fraca: Entregas inconsistentes e falta de responsabilidade
Equipe despreparada e gestão fraca geram entregas inconsistentes e falta de responsabilidade, expondo sua empresa a perda de clientes. Identificar falhas operacionais e estruturar governança rápida reduz riscos e restaura confiança em clientes críticos.
Reforço prático: treinar, medir e responsabilizar
Uma equipe sem treinamento adequado e sem processos claros transforma um problema técnico em crise comercial. Erros empresas de ti perderam clientes como evitar dependem de roteiro: combinação de atualizacao de skills, regras de acesso e definição de responsabilidades. Comece com avaliações trimestrais de competência, checklists de deploy e políticas de seguranca integradas ao sistema de gestão. Use a Gestão de TI para padronizar fluxo de trabalho e reduzir falhas humanas em produção.
Implementar métricas reais — tempo médio para resolver, taxa de retrabalho, e percentual de entregas no prazo — transforma sensação subjetiva em ação. Quando a equipe repete o mesmo erro, a perda de confiança do cliente cresce; monitoramento constante demonstra progresso. Exemplo: um software bancário corrigiu perda de transações após treinar quatro desenvolvedores e criar um playbook de incidentes, reduzindo retrabalho em 62% e riscos legais junto ao banco.
Governança fraca exige reforço imediato: escalonamento claro, regras de revisão de código, e atualizacao de ambientes de teste. Abaixo há um plano de três frentes acionáveis para recuperar controle e evitar que todo o projeto vire ponto de atrito. Incluar stakeholders no ciclo de revisão garante que comunicação e responsabilidades fiquem registradas no sistema e que soluções sejam aplicadas com rapidez.
Mapear responsabilidades: atribuir dono por entrega, OKR por sprint e regra de escalonamento claro.
Treinamento prático mensal: simulações de incidentes, revisão de código e workshops em software crítico.
Medir e publicar métricas: SLA, taxa de retrabalho e tempo de resposta para identificar problema rapidamente.
Implantar governança leve: listas de verificação, regras de acesso mínimas e aprovações para deploy em produção.
Indicador monitorado | Contexto ou explicação |
Indicador monitorado | Contexto ou explicação |
Ticket médio mensal | R$ 480 considerando planos com fidelidade em 2024 |
Taxa de renovação anual | 82% dos contratos com suporte personalizado |
Responsabilizar pessoas e processos reduz riscos reais; responsabilidade visível é a melhor solucao contra perda de clientes.
Aplique treinamentos, métricas e governança leve imediatamente para transformar situação atual em operação previsível e restaurar confiança do cliente.
Conclusão
Os sete erros reunidos mostram padrões evitáveis: falhas de comunicação, suporte deficiente, escalabilidade negligenciada, preços confusos, onboarding fraco, falta de foco no cliente e ausência de métricas. Cada ponto admite correções táticas imediatas e sistemáticas.
Priorize remendos rápidos e processos duradouros
Comece com ações de impacto rápido: mapear a jornada do cliente em 72 horas, criar checklists de onboarding e instituir SLAs claros para atendimento. Empresas que reduziram tempo médio de resposta de suporte em 50% viram churn cair em dois dígitos; esses ajustes demandam pouco investimento e geram retorno mensurável.
Implemente ciclos de feedback trimestrais com clientes-chave e métricas operacionais vinculadas a bônus de equipe. Exemplo prático: uma provedora ajustou pacotes após entrevistas com 12 clientes e recuperou 18% do MRR perdido. Documente mudanças e comunique benefícios ao cliente para recompor confiança rapidamente.
Adote governança mínima: dashboard com tickets, NPS, taxa de renovação e tempo de resolução; reuniões semanais de 30 minutos para decisões táticas; plano de mitigação por perda de cliente. Essas ações conectam diagnóstico a resposta prática, evitando repetir padrões que geram churn.
Revisar onboarding e contratos em 30 dias
Estabelecer SLA e monitoramento contínuo
Criar rotina de feedback e ajustes trimestrais
Indicador monitorado | Contexto ou explicação |
Indicador monitorado | Contexto ou explicação |
Ticket médio mensal | R$ 480 considerando planos com fidelidade em 2024 |
Taxa de renovação anual | 82% dos contratos com suporte personalizado |
Priorize métricas que correlacionem ações a retenção: tempo de resposta, NPS e taxa de churn são alavancas diretas de lucro.
Corrija rapidamente os pontos fracos mapeados, mensure resultados e transforme correções pontuais em processos contínuos para evitar perdas sustentadas de clientes.
Perguntas Frequentes
Quais são os erros mais comuns que fizeram empresas de TI perderam clientes e como evitar?
Os erros mais comuns incluem comunicação falha, suporte técnico lento, promessas não entregues, falhas de segurança e gerenciamento de projetos ineficiente. Para evitar, implemente processos claros de atendimento ao cliente, SLAs realistas, revisão contínua de segurança da informação e metodologias ágeis que permitam entregas iterativas e visibilidade para o cliente.
Investir em treinamento da equipe, automação de tickets e feedback estruturado também reduz churn e melhora retenção de clientes. A combinação de transparência, documentação e acompanhamento proativo resolve grande parte dos problemas que causam perda de clientes.
Como identificar sinais de que estamos prestes a perder um cliente na área de TI?
Sinais comuns incluem queda no uso do serviço, aumento de reclamações, falta de resposta a propostas comerciais e atrasos frequentes em pagamentos. Monitorar métricas como NPS, tempo de resolução de chamados e taxa de churn ajuda a detectar problemas cedo.
Procure por feedback negativo recorrente sobre suporte técnico ou comunicação; ações corretivas rápidas — como contato direto do gerente de conta e planos de recuperação — costumam reter clientes antes que eles procurem concorrentes.
Quais estratégias práticas evitam que erros empresas de ti perderam clientes como evitar novos cancelamentos?
Implemente um processo de onboarding robusto, SLAs bem definidos e revisões periódicas com o cliente. Use automação para acompanhamento de tickets e alertas em indicadores críticos; isso melhora o tempo de resposta e a qualidade do suporte técnico.
Além disso, mantenha um canal de comunicação transparente, ofereça treinamentos e crie roadmaps colaborativos. Essas ações aumentam a confiança do cliente e reduzem o risco de churn por problemas operacionais ou de alinhamento.
Como melhorar o suporte técnico sem aumentar muito os custos?
Automatize tarefas repetitivas com base de conhecimento, chatbots para triagem e fluxos de atendimento que encaminhem para o nível certo. Treine a equipe para resolver problemas no primeiro contato e use métricas para identificar gargalos que geram retrabalho.
Outra opção é priorizar proativamente clientes estratégicos com planos diferenciados e utilizar outsourcing para picos de demanda. Essas medidas elevam a eficiência do atendimento ao cliente sem aumentar proporcionalmente o custo.
Quais práticas de gestão de projetos ajudam a evitar falhas que fazem empresas de TI perderem clientes?
Adoção de metodologias ágeis, entregas incrementais e checkpoints regulares com o cliente garantem alinhamento contínuo. Planejamento realista, gerenciamento de riscos e documentação clara evitam expectativas irreais e reduzem retrabalho.
Ferramentas de gestão que permitem transparência (como quadros Kanban e relatórios de progresso) ajudam o cliente a acompanhar o valor entregue, diminuindo a percepção de atraso ou falta de compromisso.
Como a segurança da informação influencia na retenção de clientes e como mitigar riscos?
Incidentes de segurança minam a confiança e podem levar à perda imediata de clientes, além de danos reputacionais. Para mitigar riscos, implemente políticas de segurança, atualize sistemas, faça testes de invasão regulares e treine funcionários em boas práticas.
Comunique-se proativamente sobre medidas de proteção e planos de contingência; clientes valorizam fornecedores que demonstram responsabilidade com dados e continuidade, o que melhora a retenção e reduz a probabilidade de cancelamentos por insegurança.